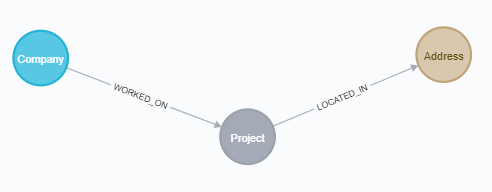
I'm having a hard time optimizing a query to get co-occurrence data from my graph. The data in my graph represents projects and companies working on them. I'm trying to get data on how often each company worked with each of the other companies on a project located in the same address. Here's the part of my schema that is relevant to this query:
And here's my query:
MATCH (company:Company)-[:WORKED_ON]->(project:Project)-[:LOCATED_IN]->(address:Address)
WITH DISTINCT company, address
MATCH (other_company:Company)-[:WORKED_ON]->(other_project:Project)-[:LOCATED_IN]->(address)
WHERE company <> other_company
WITH company, other_company, COUNT(DISTINCT address) AS frequency ORDER BY frequency DESC
RETURN
company.uuid,
COLLECT(other_company.uuid + ': ' + frequency) AS co_occurrence
This query should return all companies in the graph and for each return an array of other companies that worked on a project in the same address, along with a frequency of how often that occurred for that pair of companies.
Here's an example output when I run the query on a smaller subset of companies:
My graph size is ~25GB. I tried running the query with 30GB cache and 30GB heap allocated to Neo4j. I'm running Neo4j 3.5.1.
My graph has 1.7M company nodes, 4.9M project nodes, and 3.5M address nodes. There's about 11M WORKED_ON relationships between companies and projects. Here's the result of running EXPLAIN on my query:
I can get the query to return results within a couple of minutes when I limit the number of companies to 10k. Once I go to 100k I can't get it to return results. It runs forever and eventually brings Neo4j down.
Any suggestions for how I can optimize this query?
Thank you for your question. Yes, for the nodes involved in this query, I have one UNIQUE constraint on the Address node:
ON ( address:Address ) ASSERT address.full_address IS UNIQUE
I also have the following indexes:
ON :Address(street_address_lower) ONLINE
ON :Address(uuid) ONLINE
ON :Company(cohort_id) ONLINE
ON :Company(name_lower) ONLINE
ON :Company(publish_score) ONLINE
ON :Company(uuid) ONLINE
ON :Project(uuid) ONLINE
ON NODE:Company(name) ONLINE
ON :Address(full_address) ONLINE (for uniqueness constraint)
I saw there were uuids on Company and Project nodes so you can use them to create the unique constraints:)
Generally, it's a good practice to create a unique constraint on a property that will be different for each node like a product id for example or a company id:)
The unique constraint on id will help Neo4j to speed up the query but you can still add unique constraint on another property if you want them unique:)
Thanks, @cobra. I added the UNIQUE constraint for the 3 nodes. It seemed to speed things up slightly when I limit the number of companies. But I still can't the query to run on the entire graph.
I'm having similar issues with co-occurrence link creation. I am trying to create bi-partite links between any two authors that have the same publishers. When the number of items are small, the query finishes in a matter of minutes. But as you increase the numbers, the query almost never finishes. My PC already has 64gb of ram (which is only 80% used) and core i7 10th gen (16 virtual cores that is only 30% used). All drives are SSDs with 1 to 3% usage.
Is there a better way to code this query below:
Match (n:Author)-[:HasPublisher]->(p:Publisher)
WHERE EXISTS(n.Last) AND EXISTS(n.First) AND LEFT(p.Name,1)='A'
WITH n,p as pubs
UNWIND pubs as publish
// find other authors published by same publisher
Match (publish)<-[:HasPublisher]-(a:Author)
WHERE EXISTS(a.Last) AND EXISTS(a.First) AND n.Orcid<>a.Orcid AND n.First <>a.First AND n.Last <> a.Last
Merge (n)-[:SamePublisher{Name:publish.Name}]->(a)
Notice that i already deliberately limited the returned items by filtering for only publishers with names starting with "A". and still the query never finishes!
Im now wrapping it inside a call apoc.periodic.iterate
CALL apoc.periodic.iterate(
“cypher runtime=slotted
MATCH (n:Author)-[:HasPublisher]->(p:Publisher)<-[:HasPublisher]-(a:Author)
WHERE EXISTS(n.Last) AND EXISTS(n.First) AND EXISTS(a.Last) AND EXISTS(a.First) AND n.Orcid<>’NONE’ AND a.Orcid<>’NONE’ AND n.Orcid<>a.Orcid AND n.First <>a.First AND n.Last <> a.Last
Merge (n)-[r:SamePublisher]->(a)”,
“ON create set r.Name=p.Name”,
{batchsize:500, parallel:true, iterateList:true}
)
I assume that you are using the latest version of Neo4j:
MATCH (a:Author)-[:HasPublisher]->(p:Publisher)<-[:HasPublisher]-(b:Author)
WHERE EXISTS(a.Last) AND EXISTS(a.First) AND EXISTS(b.Last) AND EXISTS(b.First)
MERGE (a)-[r:SamePublisher {Name: p.Name}]->(b)
CALL apoc.periodic.iterate('
MATCH (a:Author)-[:HasPublisher]->(p:Publisher)<-[:HasPublisher]-(b:Author)
WHERE EXISTS(a.Last) AND EXISTS(a.First) AND EXISTS(b.Last) AND EXISTS(b.First)
RETURN a, b, p
', '
MERGE (a)-[r:SamePublisher {Name: p.Name}]->(b)
', {batchSize: 1000})
Hi Cobra Maxime, Thanks for looking into this. To answer your question. I am NOT using the latest 1.3.10 (this version does not allow me to save into a different folder location). I am currently using 1.3.4.
The graph database has 1.3m nodes and 43m relationships so far. The Database folder is about 2.36GB
Hi Cobra Maxime. Neo4j Desktop is version 1.3.4.
I have 64gb ram
I did run your code, it's been over 13 hours now... and still running.
It is still running. The db size has grown from 2.36 gb to now 239 gb.
I see that relationships has grown from 43m to now 458M and growing.
Hi there is a difference between Neo4j Database, Neo4j Desktop and Neo4j Browser. I need to know the configuration of the Neo4j Database (version, RAM, etc.). There is a difference between the computer has 64gb of RAM and the database has 64gb of RAM.
Have you used UNIQUE CONSTRAINT to create your nodes?