

(Image source: 新型冠状病毒不耐高温 还怕这个东西 ::: 六度网)
*Compiled and translated with the permission from the author. The original article was published at: http://we-yun.com/index.php/virus/120.html by Zhi Zhang from we-yun.com. *
China is facing an unprecedented epidemic, the Corona Virus. Various means of transportation have become a major way of virus transmission. During the Spring Festival (Chinese New Year), returning home to visit relatives and returning to work again had to take planes, trains, coaches, buses, subways, ships, taxis and other means of transportation, and it is inevitable that there are chances people may travel with carriers of the virus, who may or may not show symptoms. For normal residents, the best they can do to help winning the fight against this virus is to find out whether there was any possible contact with known petients, from published reports which indicated any public transportation those patients had been to.
Several open source projects have been built by volunteers to provice query tools for people to do self assessment. Epidemic Search is one of those initiatives which was developed to meet this urgent need. Here is the home page of Epidemic Search: http://v.we-yun.com:2020/browser/
If you want to know if you'd ever been on a plane, train, subway, or somewhere with someone with the virus, just open to the link above and and enter a name of place(such as "Beijing", "Beijing, Wuhan", "Beijing, Wuhan, Shanghai", etc.), flight, train or even license plate. The first time it may take longer to launch so please be patient.

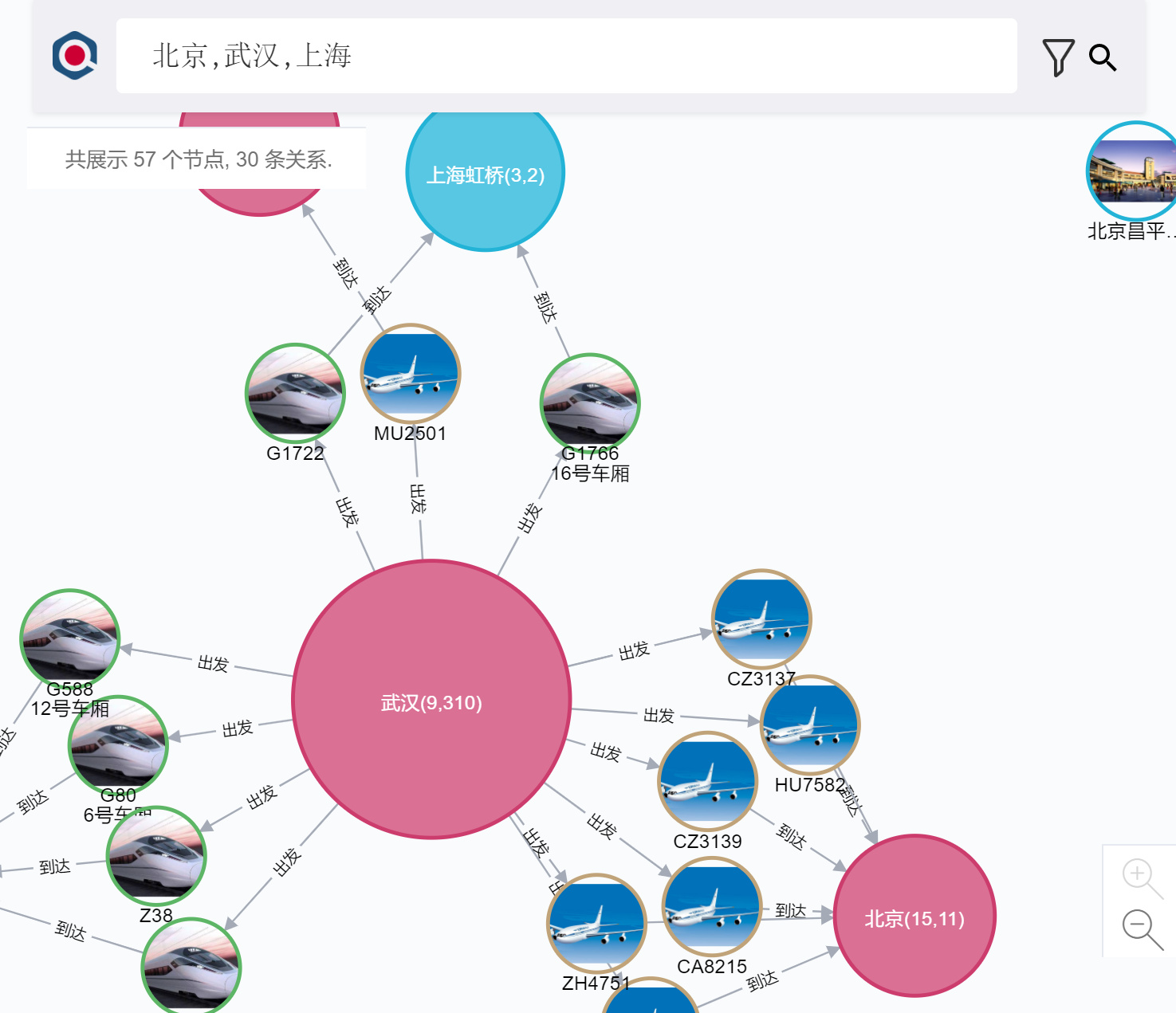
The graph above shows all known cases that are connected with the name.
If you enter "Beijing, Wuhan", the graph shows flight, train and vehicle license plate that have had confirmed cases between this two cities.

You can get even bigger graph by querying names of say 3 cities:
The source data is shared by https://2019ncov.nosugartech.com in JSON format. Neo4j APOC procedure (called within Cypher ) was used to parse JSON data, and other procedures to extract content to create nodes, relationships and properties:
// Create index before loading data
call db.index.fulltext.createNodeIndex("名称",["地点","飞机","火车", "地铁", "长途", "公交", "出租", "轮船", "场所"],["名称"]);
WITH "https://2019ncov.nosugartech.com/data.json" AS url
CALL apoc.load.json(url) YIELD value
UNWIND value.data AS item
// Create / merge Locaton and Vehicle nodes
with item,
['飞机', '火车', '地铁', '长途', '公交', '出租', '轮船', '场所'][item.t_type-1] as type,
['航班', '车次', '线号', '车牌', '车牌', '车牌', '船次', '名称'][item.t_type-1] as no_name
call apoc.merge.node([type], {id:item.id},
{
名称:item.t_no + case when item.t_no_sub='' then '' else ' ' + item.t_no_sub end,
类型:type,
日期:item.t_date,
开始时间:item.t_start,
结束时间:item.t_end,
出行类型:type,
出行描述:item.t_memo,
车厢:item.t_no_sub,
出发站:item.t_pos_start,
到达站:item.t_pos_end,
线索来源:item.source,
线索人:item.who,
更新时间:item.updated_at,
image:'http://we-yun.com/image/交通工具/'+type+'.png'
},
{}) yield node
// Create start node
with item, node where item.t_pos_start<>''
merge (p1:地点 {名称:item.t_pos_start})
// Create end node
with item, node, p1 where item.t_pos_end<>'' and item.t_pos_start<>item.t_pos_end
merge (p2:地点 {名称:item.t_pos_end})
// Create relationships to connect Start and End nodes
merge (p1)-[r1:出发]->(node)-[r2:到达]->(p2)
return count(r2);
The graph model is very simple to understand, i.e. places that are connected by methods of transportation:

Now, to query this knowledge graph is just a matter of matching start and / or end nodes by their names, and traverse relationships in between using allShortestPaths.
To learn more about APOC procedures, please visit: Neo4j APOC Library - Developer Guides
To learn Cypher, the pattern matching language for graph, please visit: Cypher Query Language - Developer Guides
Special thanks to: we-yun.com who is one of the key Solution Partners of Neo4j in China. https://2019ncov.nosugartech.com/ who provided case data.
