
Discover AuraDB Free: Week 18 — Importing GEDCOM Files and Exploring Genealogy/Ancestry Data as a Graph
Two weeks ago, a colleague asked if I could help him import his personal ancestry data into Neo4j. He sent me a GEDCOM file, and I gave it a try.
If you missed our live-stream, here is the recording:
https://medium.com/media/29155edbbc2ac9d36cb0016c406e1741/hrefAs you can guess family trees are much better handled as a graph than as a bunch of text fragments.
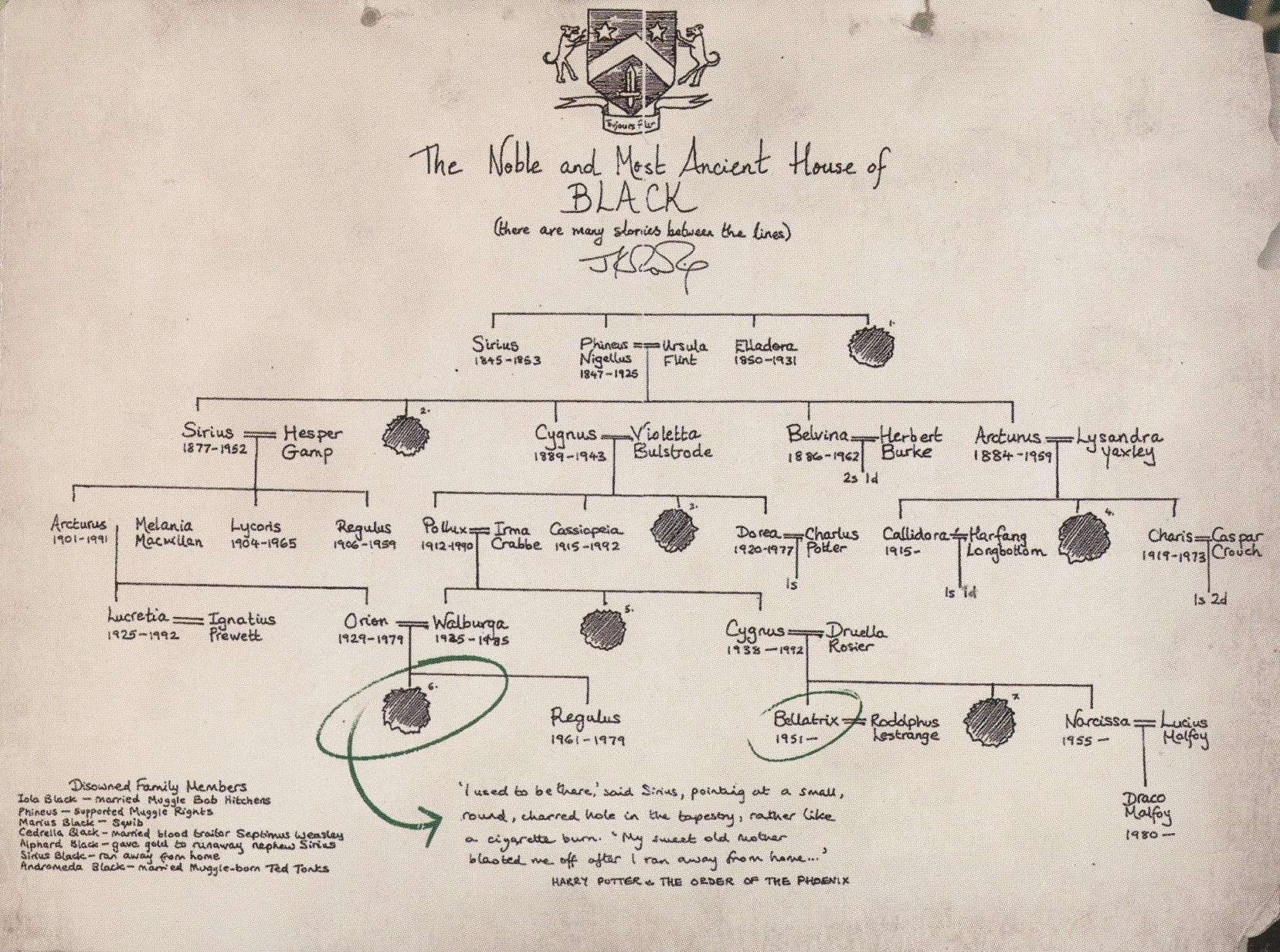
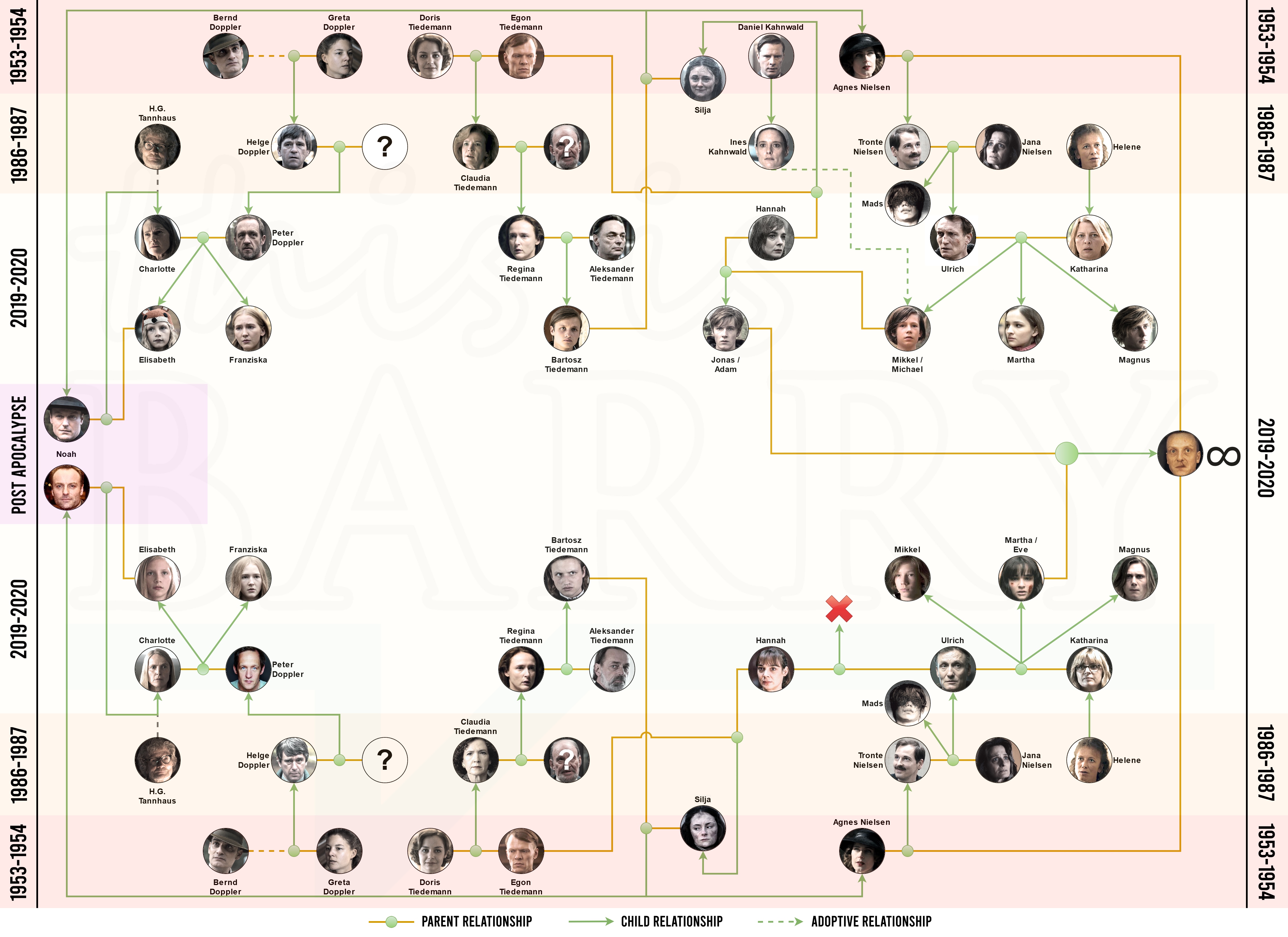
Here are some examples from history and pop-culture, from the royal family, to Sirius Black family tree in Harry Potter and the complex Game of Thrones relationships and the amazing Netflix Series “Dark” that I just started re-watching my daughters (Spoilers hidden behind links).
{kind=link}
{kind=link}
{kind=link}
I looked at the GEDCOM file format (see below) and was reminded of a COBOL data file format (or formats I used in the long past for storing data myself).
I remembered that my friend and colleague Rik van Bruggen had imported his ancient family history into Neo4j 8 years ago (also using gedcom but with some desktop application).
But I wanted to have something simple that I could run on the command line.
First thing I found was a tool written in go that was quite intriguing because it allowed to query GEDCOM files with a syntax similar to the JSON tool jq. You could extract individual attributes of a person as well as relationships to parents, children, etc.
./gedcom query -format csv -gedcom ~/Downloads/pres2020.ged '.Individuals | { name: .Name | .String, born: .Birth | .String, died: .Death | .String, id: .Identifier, sex:.Sex, parents:.Parents | .Identifier, parentNames:.Parents }' | head -3born,died,id,name,parentNames,parents,sex
,,@I2184@,Paul Stobbe,[],[],Male
19 Aug 1946,,@I1@,William Jefferson Clinton,"[William Jefferson Blythe II (b. 27 Feb 1918, d. 17 May 1946) ⚭ Virginia Dell Cassidy (b. 6 Jun 1923, d. Jan 1994)]",[@F2@],Male
But, unfortunately, I couldn’t figure out how to return the IDs of the parents, only their names, which are not unique.
So I looked further and found this really useful Python library that allows you to parse and query GEDCOM files.
Datasets
As I cannot share the person information from my colleague, I found some public GEDCOM datasets that we can use.
There are datasets for the British Royals, US-Presidents, Shakespeare, Brontë. We’ll use the first two in our exploration.
Here is an example section from the presidents file, as you can see parsing that format would be quite tedious.
1 NAME Barack Hussein /Obama/ II
2 SOUR @S48@
3 PAGE Gale Research Company; Detroit, Michigan; Accession Number: 922392
3 DATA
4 TEXT Record for Dr. Barack Hussein Obama
3 _LINK https://search.ancestry.com/cgi-bin/sse.dll?db=4394&h=10717780&indiv=try
1 SEX M
1 BIRT
2 DATE 4 AUG 1961
2 PLAC Honolulu, Honolulu, Hawaii, USA
3 MAP
4 LATI N21.3069
4 LONG W157.8583
2 SOUR @S48@
3 PAGE Gale Research Company; Detroit, Michigan; Accession Number: 922392
3 DATA
4 TEXT Record for Dr. Barack Hussein Obama
3 _LINK https://search.ancestry.com/cgi-bin/sse.dll?db=4394&h=10717780&indiv=try
1 OCCU US President No. 44, Democratic
2 DATE 20 JAN 2009
2 PLAC Washington, District of Columbia, USA
3 MAP
4 LATI N38.895
4 LONG W77.0367
1 _PHOTO @M26@
1 OBJE @M26@
1 FAMS @F1061@
1 FAMC @F1105@
Pre-Processing with Python
The python-gedcom library has a parser that reads a file and then allows to inspect it’s element and provide methods to provide attributes for each element.
Elements can be IndividualElement, FamilyElement, FileElement or ObjectElement, here we’re interested in the IndividualElement and its attributes.
Our our Python script, we iterate over the elements of the file and for the people (individuals), we get the
- first name
- last name
- year of birth
- year of death
- sex
- id (pointer)
There is much more data available, but for our model these attributes are good enough.
For the parental information mother and father we get the parent’s entries for this individual from the parser and filter them by gender and get their ids to constitute the relationships later.
In the datasets we’re looking at here, there are only male and female as genders and binary parents, for real data we can extend this.
We’ll put all that data into a list and output it as comma separated lines, in a real tool, we’d use dataframes for that.
https://medium.com/media/d56cbcfbd56650c73e0f672b835f6e6b/hrefYou pass the GEDCOM file as the argument to the script and redirect the output into a CSV file.
python3 gedcom2csv.py pres2020.ged > presidents.csv
Example output from presidents file.
Now we can take these CSV files and import them into Neo4j.
Data Model
The data model is really straightforward, just a Person node with the attributes like first, last-name, birth and death-years, sex and id.
Then we have relationships MOTHER and FATHER to other persons based on the ids.
Create a Neo4j AuraDB Free Instance
Go to https://dev.neo4j.com/neo4j-aura to register or log into the service (you might need to verify your email address).
After clicking Create Database you can create a new Neo4j AuraDB Free instance. Select a Region close to you and give it a name, e.g. {db-name}.
Choose the “blank database” option as we want to import our data ourselves.
On the Credentials popup, make sure to save the password somewhere safe. The default username is always neo4j.
Then wait 3–5 minutes for your instance to be created.
Afterwards you can connect via the Open Button with Neo4j Browser (you’ll need the password).
Then also the connection URL: neo4j+s://xxx.databases.neo4j.io is available and you can copy it to your credentials as you might need it later.
If you want to see examples for programmatically connecting to the database go to the “Connect” tab of your instance and pick the language of your choice.
Import
As before we use the handy, upcoming data importer visual tool for Neo4j to import the data (see the video).
- Load the file
- Create the person node
- Map properties from the file (except for mother and fatehr)
- Select the id as id property
- Drag out the relationship and connect it back to the node again to create a “self relationship”, name one FATHER and one MOTHER
- Map the file again to the relationships from id to the ids of mother and father respectively
Then use the connection URL from your AuraDB Free instance, and the password you hopefully saved into the Run Import form and click Run.
After a few seconds you should see these results. For each graph element you can show the constraint creation and the actual import statement, that you could use in your own code.
First Exploration with Neo4j Browser
We want to extend the data in the database a bit with additional, inferred information.
You can open “Neo4j Browser” from your AuraDB Free instance to execute the statements, you need the password again to log in.
There we can start exploring, by opening the left sidebar and clicking on the relationship-count.
Then we see the graph data and can select one of the existing properties to be displayed as caption.
As both last and first names are not conclusive let’s combine them into a name property, which makes it nicer to display our data.
MATCH (p:Person)
SET p.name = p.first + ' ' + p.last;
CREATE INDEX ON :Person(name);
So we can pick that for the display and see data.
We can also query our data directly, e.g. if we want to see the “Kennedy” families down to arbitrary relationship depth.
MATCH path=(p:Person)<-[*]-()
WHERE p.last = 'Kennedy'
RETURN path
Visualization with Neo4j Bloom
Neo4j Browser is more a developer tool, for writing, executing Cypher queries and visualizing their results.
Neo4j Bloom is a no-code visualization and exploration tool. You can just start typing in Graph patterns into the search bar or if you have indexes (like ours on Person(name)) just type the name, hit return and see a beautiful graph visualization that you then can explore further.
You can layout the graph data both as force graph and hierarchical layouts, the latter is especially interesting with hierarchical data like our ancestry.
So let’s try it, open Neo4j Bloom from your AuraDB Open Button and log in with username (neo4j) and your password.
Enter: “Abraham Lincoln Person Person” into the search bar, select the graph pattern and hit return.
You should see something like this:
If you want to see all the data, just
- enter: “Person” into the search bar
- select all nodes with ctrl/cmd+a
- right click on a node and choose Expand→All
What was surprising to me, was the long chains of parental relationships going all the way through the presidential data and not a lot of isolated islands of subgraphs.
Perhaps the US is not so far from a inheritance of power after all :)
I styled the relationship by color, but you could also style the nodes with icons, color them by unique values (e.g. male/female) or size them by the year people were born in (more recent→bigger) or the number of children/ancestors (currently would need a property on the node for the styling).
Here is an example for a styled graph.
Adding New Relationships
Of course we can add new, inferred relationships to our data, either from itself or by integrating it with external data.
In our example, we want to:
- Add a “global” family by name
- Add a core-family to it’s members
- Add sibling relationships
Adding Family nodes
The “global family” is not 100% correct, as we create a global ancestral Family node just by last-name and connect every person with the same last name to it (think “Smith”).
MATCH (p:Person)
MERGE (fam:Family {name:p.last})
MERGE (p)-[:FAMILY]->(fam);
But we can spot use it to spot a common family that we’re sure of.
Another option is to create a CoreFamily for each parents-children family, so we would create the CoreFamily node in context of (one of) the parents.
As either parent could be not existing, we would use a fallback mechanism to create that core-family for a person.
MATCH (p:Person)
// parents might not be there
OPTIONAL MATCH (p)-[:FATHER]->(f)
OPTIONAL MATCH (p)-[:MOTHER]->(m)
WITH p, coalesce(f,m,p) as root,
// non-null members
[member in [f,m,p] WHERE NOT member IS NULL] as members
// create family in context of root person
MERGE (root)-[:CORE_FAMILY]->(fam:CoreFamily)
SET fam.name = root.last
WITH members, fam
UNWIND members as member
MERGE (member)-[:CORE_FAMILY]->(fam);
What we could then do is to connect the core-families from one generation to the next:
MATCH (curr:CoreFamily)<-[:CORE_FAMILY]-
(member)-[:CORE_FAMILY]->(ancestors:CoreFamily)
WHERE exists {
(parent)-[:CORE_FAMILY]->(ancestors:CoreFamily),
(member)-[:FATHER|:MOTHER]->(parent)
}
MERGE (curr)-[:ANCESTORS]->(ancestors);
Family Ancestry for the Kennedy Family in Neo4j Browser
Family Ancestry in Hierarchical Layout in Bloom
We can derive siblings from two people having a joint parent, in our case one joint parent is enough, we could also change the query where both parents need to be the same.
Siblings with Single Shared Parent
// from person to parents
MATCH (p:Person)-[:MOTHER|FATHER]->(parent)
// other person that shares a parent
MATCH (sib:Person)-[:MOTHER|FATHER]->(parent)
// not the same person
WHERE p <> sib
// create a sibling relationship (undirected)
MERGE (p)-[:SIBLING]-(sib);
Siblings with Two Shared Parents
// from person to parents
MATCH (dad)<-[:FATHER]-(p:Person)-[:MOTHER]->(mom)
// other person that shares a parent
MATCH (dad)<-[:FATHER]-(sib:Person)-[:MOTHER]->(mom)
// not the same person
WHERE p <> sib
// create a sibling relationship (undirected)
MERGE (p)-[:SIBLING]-(sib);
If we look at some of them we see binary to 7 sided sibling clusters.
Direct Import with the Python Driver
Instead of exporting a CSV file we can also directly write the data to Neo4j.
In a copy of our script, we install the neo4j driver dependency and add the import for GraphDatabase.
The information for the NEO4J_URI and NEO4J_PASSWORD comes from environment variables that we need to set to our connection details from Neo4j Aura. We use that information to create our driver.
Instead of creating and outputting a row list for each individual person, we populate a dict per and add it to a data list.
The Cypher statement that we use to create our node data in Neo4j can be directly copied from data importer.
The relationships to the parents are tiny bit more tricky as either of them might not be there in the data.
So either we could:
- Run a double-pass over the data filtering out individuals that have no parents of the current type
- Add a conditional subquery to add the relationship
- Default to an “unknown” Parent and clean up after
#!/usr/bin/python3
# usage: NEO4J_URI="bolt://localhost" NEO4J_PASSWORD=secret ./gedcom2neo4j.py file.ged
# https://pypi.org/project/python-gedcom/
# https://pypi.org/project/neo4j/
import sys
import os
from gedcom.element.individual import IndividualElement
from gedcom.parser import Parser
from neo4j import GraphDatabase
driver = GraphDatabase.driver(os.getenv('NEO4J_URI'), auth=("neo4j", os.getenv('NEO4J_PASSWORD')))file_path = sys.argv[1]
gedcom_parser = Parser()
gedcom_parser.parse_file(file_path)
root_child_elements = gedcom_parser.get_root_child_elements()
statement_w_cleanup = """
UNWIND $data as row
MERGE (p:Person {id:row.id})
SET p += row {.first, .last,.sex,
death: toInteger(row.death),birth:toInteger(row.birth)}
SET p.name = p.first + ' ' + p.last
MERGE (m:Person {id:coalesce(row.mother,'unknown')})
MERGE (p)-[:MOTHER]->(m)
MERGE (f:Person {id:coalesce(row.father,'unknown')})
MERGE (p)-[:FATHER]->(f)
WITH count(*) as total
MATCH (d:Person {id:'unknown'})
DETACH DELETE d
RETURN distinct total
"""
statement_conditional = """
UNWIND $data as row
MERGE (p:Person {id:row.id})
SET p += row {.first, .last,.sex,
death: toInteger(row.death),birth:toInteger(row.birth)}
SET p.name = p.first + ' ' + p.last
CALL { WITH row, p
WITH * WHERE NOT coalesce(row.mother,'') = ''
MERGE (m:Person {id:row.mother})
MERGE (p)-[:MOTHER]->(m)
RETURN count(*) as mothers
}
CALL { WITH row, p
WITH * WHERE NOT coalesce(row.father,'') = ''
MERGE (f:Person {id:row.father})
MERGE (p)-[:FATHER]->(f)
RETURN count(*) as fathers
}
RETURN count(*) AS total
"""
data = []
root_child_elements = gedcom_parser.get_root_child_elements()
for e in root_child_elements:
if isinstance(e, IndividualElement):
(first,last) = e.get_name()
row = {"first":first, "last":last}
row["birth"]=e.get_birth_year()
row["death"]=e.get_death_year()
row["gender"]=e.get_gender()
row["id"]=e.get_pointer()
parents = gedcom_parser.get_parents(e)
row["mother"]=next(iter([p.get_pointer() for p in parents if p.get_gender() == 'F']),None)
row["father"]=next(iter([p.get_pointer() for p in parents if p.get_gender() == 'M']),None)
data= data + [row]
with driver.session() as session:
total = session.write_transaction(
lambda tx: tx.run(statement_w_cleanup, data = data).single()['total'])
print("Entries added {total}".format(total=total))
One tricky aspect that we ran into in our live-stream was that the IDs of people are not unique globally but only per GEDCOM file.
So if you import the British Royals into the same database as the American First Families, you get a whole mess. It makes then either sense to prefix the id’s with the filename that they came from or try to create a more global identifier of — full-name, birthday and birth location but even that might not be unique but could at least be used to merge multiple datasets together.
Another aspect of that uniqueness check could be to check the topologicial context of an individual, i.e. with the same name, birthday, birthplace location, do they also have the same parents and/or the same children.
Conclusion
We would love to hear if this was helpful for you to import your GEDCOM files into Neo4j and what insights you found or added in terms of information.
After sharing our experiments internally we learned that actually several of our colleagues had written custom GEDCOM parsers to get their family history into Neo4j.
Happy graphing
Discover AuraDB Free: Importing GEDCOM Files and Exploring Genealogy/Ancestry Data as a Graph was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.