Hi Robert,
No worries for the confusion.
I'll explain in full detail what I'm trying to do. I'm trying to create a new method of learning which is similar to a textbook, but provides the learner the data in the form of a tree structure, where you can keep opening nodes to view more detail (This way you can decide whether you just want to get the concepts without any of the details, (to reduce cognitive load) but still have the ability to look deeper.
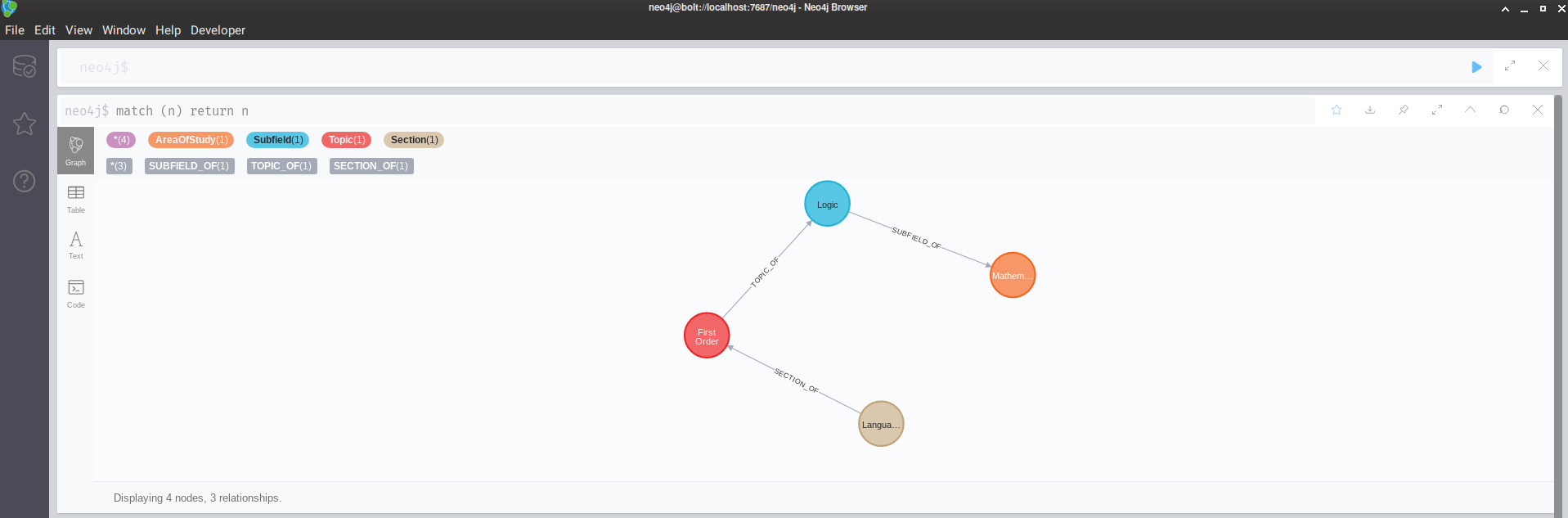
As for the data, I exported it here is a sample (shows the nesting of the definitions), thought right now the relationships saying whether a definition is included in another definition doesn't exist (the image I drew in the original post)
<outline text="Mathematics">
<outline text="Logic">
<outline text="Content">
<outline text="Structures &amp; Languages">
<outline text="Proof Techniques">
<outline text="For Proving things about terms or formulas, since they are given in terms of a recursive definition, in the base case we show it holds on the atomic elements, then in the inductive step we assume it holds on the smaller elements, and show it holds on this element. Structural Induction.">
<outline text="Example proof, is show that for any formula, the number of left parens is equal to right parens. ">
<outline text="Base case: Nothing has parens" />
<outline text="Ind Case: Consider a formula of the form 3 4 5, assume it true for the formulas that they are constructed from (alpha, beta). It's true because each of 3, 4, 5 add an even number of braces, and even + even is even." />
</outline>
</outline>
</outline>
<outline text="Definitions">
<outline text="Language">
<outline text="Definition 1.2.1: A first-order language L is an infinite collection of distinct symbols, no one of which is properly contained in another, separated into the following categories" _note="What we make stuff out of">
<outline text="Parenthesis: (, )." />
<outline text="Connectives: V, ~" />
<outline text="Quantifier: (forall)" />
<outline text="Variables: for each positive integer n: v1, v2, ..., vn, ... . The set of variable symbols will bed denoted as Vars." />
<outline text="Equality symbol: =" />
<outline text="Constant symbols: Some set of zero or more symbols" />
<outline text="Function symbols: For each positive integer n, some set of zero or more n-ary function symbols." />
<outline text="Relation symbols: For each positive integer n, some set of zero or or more n-ary relation symbols" />
</outline>
<outline text="Definition 1.3.1. Term of L" _note="Nouns of our language">
<outline text=" If L is a language, a term of L is a nonempty finite string t of symbols from L such that either:">
<outline text="1. t is a variable, or" />
<outline text="2. t is a constant symbol, or" />
<outline text="3. t :≡ ft1t2 . . . tn, where f is an n-ary function symbol of L and each of the ti is a term of L" />
</outline>
</outline>
<outline text="Definition 1.3.3. Formula of L" _note="Assertions about the objects of the structure">
<outline text="If L is a first-order language, a formula of L is a nonempty finite string φ of symbols from L such that either:">
<outline text="1. φ :≡ = t1t2, where t1 and t2 are terms of L, or" />
<outline text="2. φ :≡ Rt1t2 . . . tn, where R is an n-ary relation symbol of L and t1, t2,. . . , tn are all terms of L, or" />
<outline text="3. φ :≡ (¬α), where α is a formula of L, or" />
<outline text="4. φ :≡ (α ∨ β), where α and β are formulas of L, or" />
<outline text="5. φ :≡ (∀v)(α), where v is a variable and α is a formula of L." />
<outline text="If a formula ψ contains the subformula (∀v)(α) [meaning that the string of symbols that constitute the formula (∀v)(α) is a substring of the string of symbols that make up ψ], we will say that the scope of the quantifier ∀ is α" />
</outline>
</outline>
<outline text="Definition 1.5.1. Number Theory Language">
<outline text="The language L_NT is {0, S, +, ·, E, &lt;}, where 0 is a constant symbol, S is a unary function symbol, +, ·, and E are binary function symbols, and &lt; is a binary relation symbol. " />
</outline>
<outline text="Definition 1.5.2. Suppose that v is a variable and φ is a formula. We will say that v is free in φ if" _note="In the integral from 1 to x of 1/t dt, x is free but t is not, it doesn't make sense to choose a value for t, but it does for x">
<outline text="1. φ is atomic and v occurs in (is a symbol in) φ, or" />
<outline text="2. φ :≡ (¬α) and v is free in α, or" />
<outline text="3. φ :≡ (α ∨ β) and v is free in at least one of α or β, or" />
<outline text="4. φ :≡ (∀u)(α) and v is not u and v is free in α." />
<outline text="Note: (∀v1∀v2(v1 + v2 = 0)) ∨ v1 = S(0). Is free in v1, because it is free in the RHS, note that it is not free in LHS of or symbol" />
</outline>
<outline text="Definition 1.5.3. A sentence in a language L is a formula of L that contains no free variables." _note="It's either true or false, since there are no free vars">
<outline text="Ex: L = {0, 1, 2, +}, 1+1 = 2, and (∀x)(x+1=x)" />
</outline>
</outline>
I'm going to make it an online website using a tree-view (https://www.jstree.com/).
For example, inside of the "Mathematics" node, you would find "Logic" and "Combinatorics" (Combinatorcs omitted for brevity in the above) as children (I'm thinking this might be more of a SUBFIELD relationship, being more specific than HAS), then inside of "Combinatorics" there would be sections (SECTION) relationship
In terms of the relationships existing at runtime vs not, I'm not entirely sure how that would work, but I suppose my thought process was that I should put it inside of the database, my reasoning was from the following paragraph. (But honestly I'm not sure what the best choice is here, so any reasons you could give to help me decide would be great)
For example every time a new mathematical definition is introduced, if that definition uses any other definitions, I would like them to be able to open that definition right there and it is displayed (could be another treeview opened in a split). Also if a student is trying to prove a statement, I want them to be able to see exactly what tools they have at their disposal (IS_AVAILABLE).
Anways, hopefully this gives you more of an idea as to what I'm trying to do.
Thanks so much.



{kind=link}