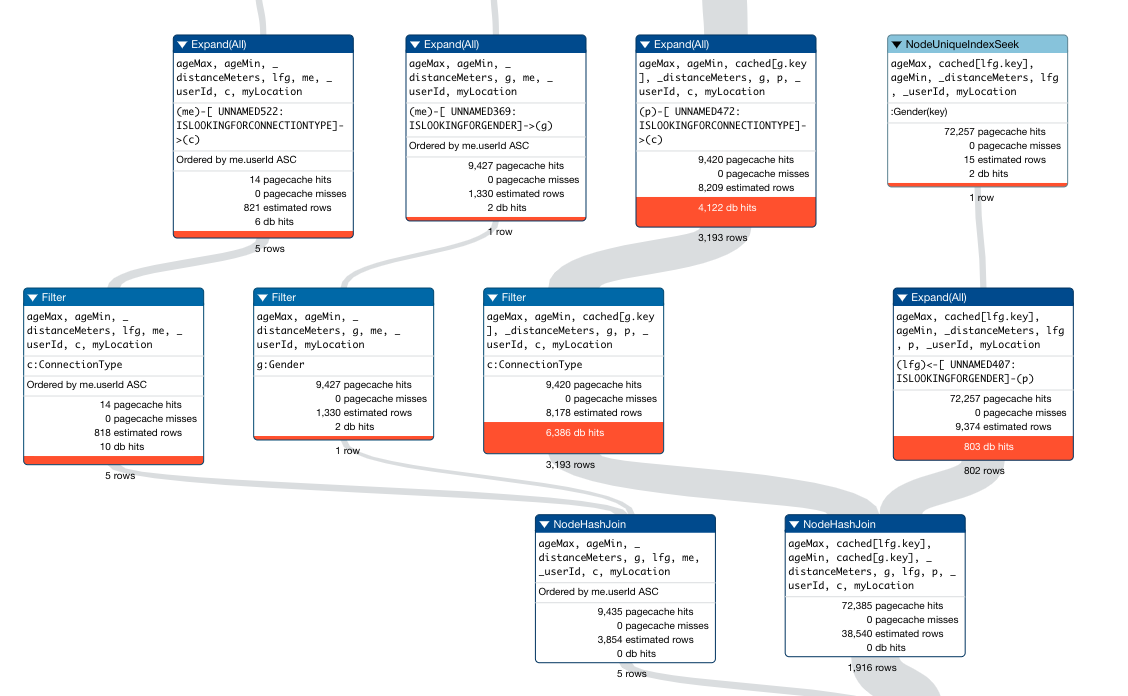
I've been working at this for a while and I've got it down to the best I can do. Before I push it out to a server, I'd like to get some input on possible ways to lower a couple of the high db hits.
I have indexes on all properties that are used in the queries. I am currently planning on converting the lastSeen, signUpStep, minAge and maxAge properties to be nodes, however it will take some time before I can get that completed.
Here's my query. The hardcoded numbers will be converted to parameters that will be passed in.
PROFILE WITH 'test123' as _userId, 48280.2 as _distanceMeters,
date.truncate('day', date() - duration({years: 18})) as ageMax, date.truncate('day', date() - duration({years: 40})) as ageMin,
point({ latitude: 30.4332061, longitude: -97.60057859999999}) as myLocation
MATCH (me:Person {userId: _userId})
MATCH (p:Person)
MATCH (p)-[:ISAGENDER]->(g:Gender)<-[:ISLOOKINGFORGENDER]-(me)
MATCH (p)-[:ISLOOKINGFORGENDER]->(lfg:Gender)<-[:ISAGENDER]-(me)
MATCH (p)-[:ISLOOKINGFORCONNECTIONTYPE]->(c:ConnectionType)<-[:ISLOOKINGFORCONNECTIONTYPE]-(me)
WHERE g.key IN [10] AND lfg.key IN [20] AND c.key IN [10,20,30,40,50]
WITH DISTINCT p, ageMin, ageMax, _distanceMeters, me, g, lfg, c, myLocation
WHERE NOT (p:Test) AND SIZE( (p)-[:DEACTIVATED]->() ) = 0
AND SIZE( (p)-[:BLOCK|BLOCKED|HAS_HIDDEN|ISAPARTNER|LIKES]->(me) ) = 0
AND distance(myLocation, p.location) < _distanceMeters
AND (CASE WHEN p.distance = 999 THEN 40072000 ELSE p.distance * 1609.34 END) > distance(myLocation, p.location)
WITH DISTINCT p, g, lfg, c, ageMin, ageMax, me
WHERE p <> me AND p.userId IS NOT NULL AND p.lastSeen IS NOT NULL AND p.signUpStep = 99 AND p.minAge IS NOT NULL AND p.maxAge IS NOT NULL
AND date.truncate('day', date() - duration({years: p.maxAge})) <= date(me.dateOfBirth) <= date.truncate('day', date() - duration({years: p.minAge}))
AND ageMin <= date(p.dateOfBirth) <= ageMax
OPTIONAL MATCH (p)-[:SPEAKS]->(l:Language)
OPTIONAL MATCH (p)-[:IS_A_FOLLOWER_OF]->(r:Religion)
OPTIONAL MATCH (p)-[:ISPOLYAMTYPE]->(pt:PolyAmType)
RETURN distinct p, collect(DISTINCT g.key) as gender, collect(DISTINCT l.key) as languages, collect (DISTINCT r.key) as religions,
collect(DISTINCT lfg.key) as lookingForGender, collect(DISTINCT c.key) as connectionType, collect(DISTINCT pt.key) as polyamtypes,
datetime({epochmillis: p.lastSeen }).month as month,
apoc.util.md5([id(p), 0]) as hash
ORDER BY month DESC, hash
SKIP 0 LIMIT 10