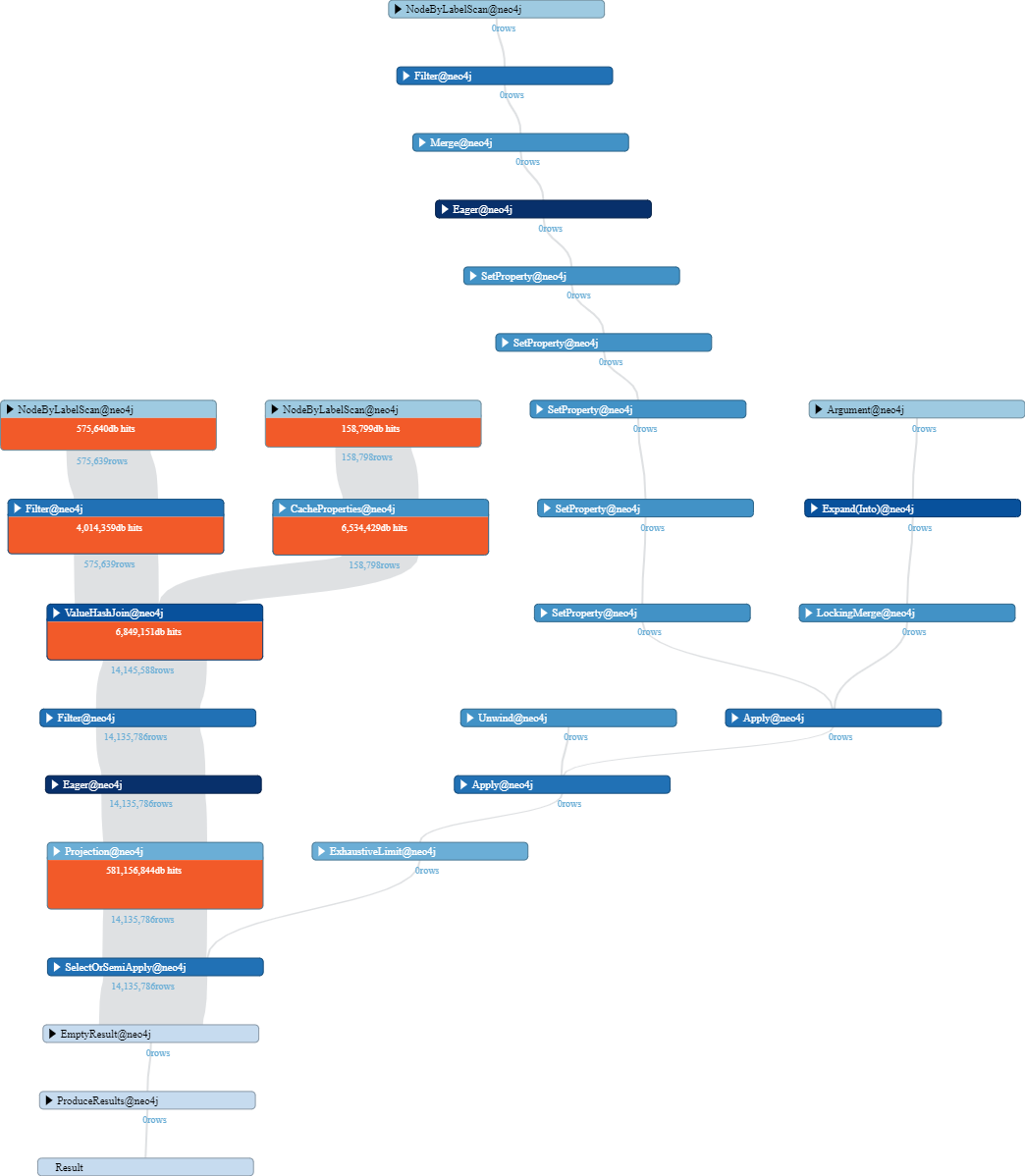
I am trying to run this MATCH between 2 labels - 1 of which has ~7M nodes and the other ~500k nodes.
The cypher query is as follows:
MATCH (a:Node1) WHERE substring(a.LogEntryTime,0,10) = toString(date()-Duration({days:1}))[Processing: PROFILE for query...]()
WITH a
MATCH (b:Node2 {Prop:a.Prop}) WHERE substring(b.LogEntryTime,0,10) = toString(date()-Duration({days:1}))
WITH a,b
FOREACH (
_ IN CASE WHEN b.Prop IS NOT null AND b.Prop2 = "Mobile" AND b.Prop3 IS NULL THEN [1] END |
MERGE (c:Node3 {Prop:b.Prop})
SET c.Prop1 = b.PropA
SET c.Prop2 = b.PropB
SET c.Prop3 = b.PropC
SET c.Prop4 = b.PropD
SET c.Prop5 = b.PropE
MERGE (c)-[:has_Node3]->(a)
)
This query is just taking way too long to execute. I have tried using index hints on a.Prop and b.Prop but it does not make the performance better. I have also tried using OPTIONAL MATCH, but that didn't help either. The join between Node1.Prop and Node2.Prop is always unique.
Attached is also the EXPLAIN/PROFILE for this query.
Any pointers to better this will be appreciated.
Try this:
Limiting the results to 10. Check to see the results. If this works, then you can use apoc.periodic.iterate (https://neo4j.com/labs/apoc/4.2/overview/apoc.periodic/apoc.periodic.iterate/)
MATCH (a:Node1) WHERE substring(a.LogEntryTime,0,10) = toString(date()-Duration({days:1}))
with a limit 10
MATCH (b:Node2) WHERE b.Prop = a.Prop
and b.Prop2 = "Mobile" and substring(b.LogEntryTime,0,10) = toString(date()-Duration({days:1}))
WITH a,b
FOREACH (ignoreMe IN CASE WHEN b.Prop IS NOT null AND b.Prop2 = "Mobile" AND b.Prop3 IS NULL THEN [1] END |
MERGE (c:Node3 {Prop:b.Prop})
SET c.Prop1 = b.PropA, c.Prop2 = b.PropB,
c.Prop3 = b.PropC, c.Prop4 = b.PropD,
c.Prop5 = b.PropE
MERGE (c)-[:has_Node3]->(a)
)
Can you create an specific label :Node for every :Node1 or :Node2 and then a property with the value substring(a.LogEntryTime,0,10) for every :Node plus an Index on this property?
It will speed up the first part of your query that already loads every :Node in order to filter.
I will check other things meanwhile.
Bennu
PS: If there's no too much writing on your db. U can create two independant Indexes for :Node1 and :Node2 in order to avoid a filter on label after using the index.