

I have been working with a fraud related dataset. The approach presented in the Neo4j Sandbox's Fraud Detection project seemed like a good starting point, so I have been trying to apply it to my data. The data set I am working with has the following labels and relationships:
(:User)-[:MEMBER_OF]->(:User) -- Representing team membership.
(:User)-[:CANONICAL]->(:Email)
(:User)-[:PAYPAL]->(:Email)
(:User)-[:ATTEMPTED_WITH]->(:Card)
(:User)-[:ATTEMPTED_WITH]->(:PayPal)
There are single-digit millions of the different node and relationship types.
I'm trying to introduce the :SHARED_IDENTIFIERS relationship described on slide 13 of the Fraud Detection playbook at https://guides.neo4j.com/sandbox/fraud-detection/index.html. That query is:
MATCH (c1:Client)-[:HAS_EMAIL|:HAS_PHONE|:HAS_SSN]->(info)
<-[:HAS_EMAIL|:HAS_PHONE|:HAS_SSN]-(c2:Client)
WHERE c1.id<>c2.id
WITH c1, c2, count(*) as cnt
MERGE (c1) - [:SHARED_IDENTIFIERS {count: cnt}] - (c2);
I have adapted that query to my dataset, trying to constrain things as much as possible. I arrived at this query:
MATCH (account1:User)-[:CANONICAL|:PAYPAL|:MEMBER_OF|:ATTEMPTED_WITH]->(info)
<-[:CANONICAL|:PAYPAL|:MEMBER_OF|:ATTEMPTED_WITH]-(account2:User)
WHERE (info:Card OR info:Email OR info:PayPal OR info:User) AND account1.user_id < account2.user_id
WITH account1, account2, count(*) AS cnt
MERGE (account1) - [:SHARED_IDENTIFIERS {count: cnt}] -> (account2)
I have the neo4j:4.0.7-enterprise docker container deployed on a 16 core 128GB RAM virtual machine. Without any additional constraints, the query ran for 36 hours, without returning. At that point the debug.log suggested that nearly all of the CPU time was being spent on garbage collection, with numerous log lines like
2020-09-11 21:55:09.173+0000 WARN [o.n.k.i.c.VmPauseMonitorComponent] Detected VM stop-the-world pause: {pauseTime=42596, gcTime=42672, gcCount=2}
2020-09-11 21:55:52.100+0000 WARN [o.n.k.i.c.VmPauseMonitorComponent] Detected VM stop-the-world pause: {pauseTime=42425, gcTime=42490, gcCount=2}
2020-09-11 21:56:35.663+0000 WARN [o.n.k.i.c.VmPauseMonitorComponent] Detected VM stop-the-world pause: {pauseTime=43162, gcTime=43167, gcCount=2}
2020-09-11 21:57:19.868+0000 WARN [o.n.k.i.c.VmPauseMonitorComponent] Detected VM stop-the-world pause: {pauseTime=43704, gcTime=0, gcCount=0}
2020-09-11 21:58:02.879+0000 WARN [o.n.k.i.c.VmPauseMonitorComponent] Detected VM stop-the-world pause: {pauseTime=42709, gcTime=42741, gcCount=2}
At Scott Marino's suggestion I tried the apoc.periodic.iterate procedure to do the query in batches. I started with a 10,000 batch size, but that didn't improve the situation, and I eventually ended up trying a batch size of 2. This was still slow, so I moved to just doing EXPLAIN and PROFILE on smaller sub-sets of the data.
I'll post the PROFILE results for a query that is only looking at the first 20 user_ids. There are only 7 User nodes that match this condition. The query is the same as above with an added WHERE clause on the user_id:
PROFILE MATCH (account1:User)-[:CANONICAL|:PAYPAL|:MEMBER_OF|:ATTEMPTED_WITH]->(info)
<-[:CANONICAL|:PAYPAL|:MEMBER_OF|:ATTEMPTED_WITH]-(account2:User)
WHERE (info:Card OR info:Email OR info:PayPal OR info:User) AND (account1.user_id < 20) AND account1.user_id < account2.user_id
WITH account1, account2, count(*) AS cnt
MERGE (account1) - [:SHARED_IDENTIFIERS {count: cnt}] -> (account2)
The query ends up taking about 20 minutes to evaluate 7 User nodes and generate 22 new SHARED_IDENTIFIER relationships between 24 different User nodes. If this scaled linearly, it would take 40 years to process the whole dataset. ![]()
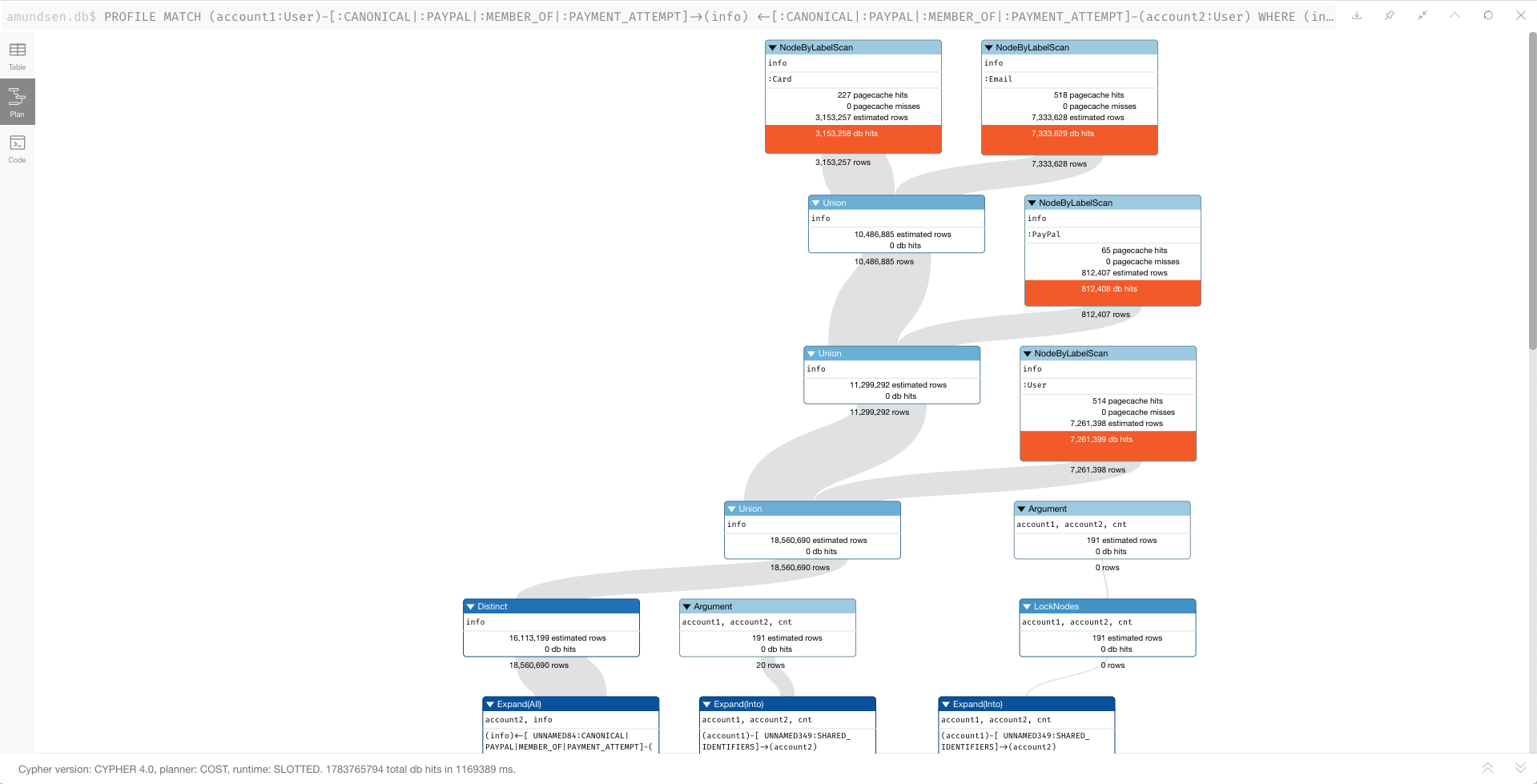

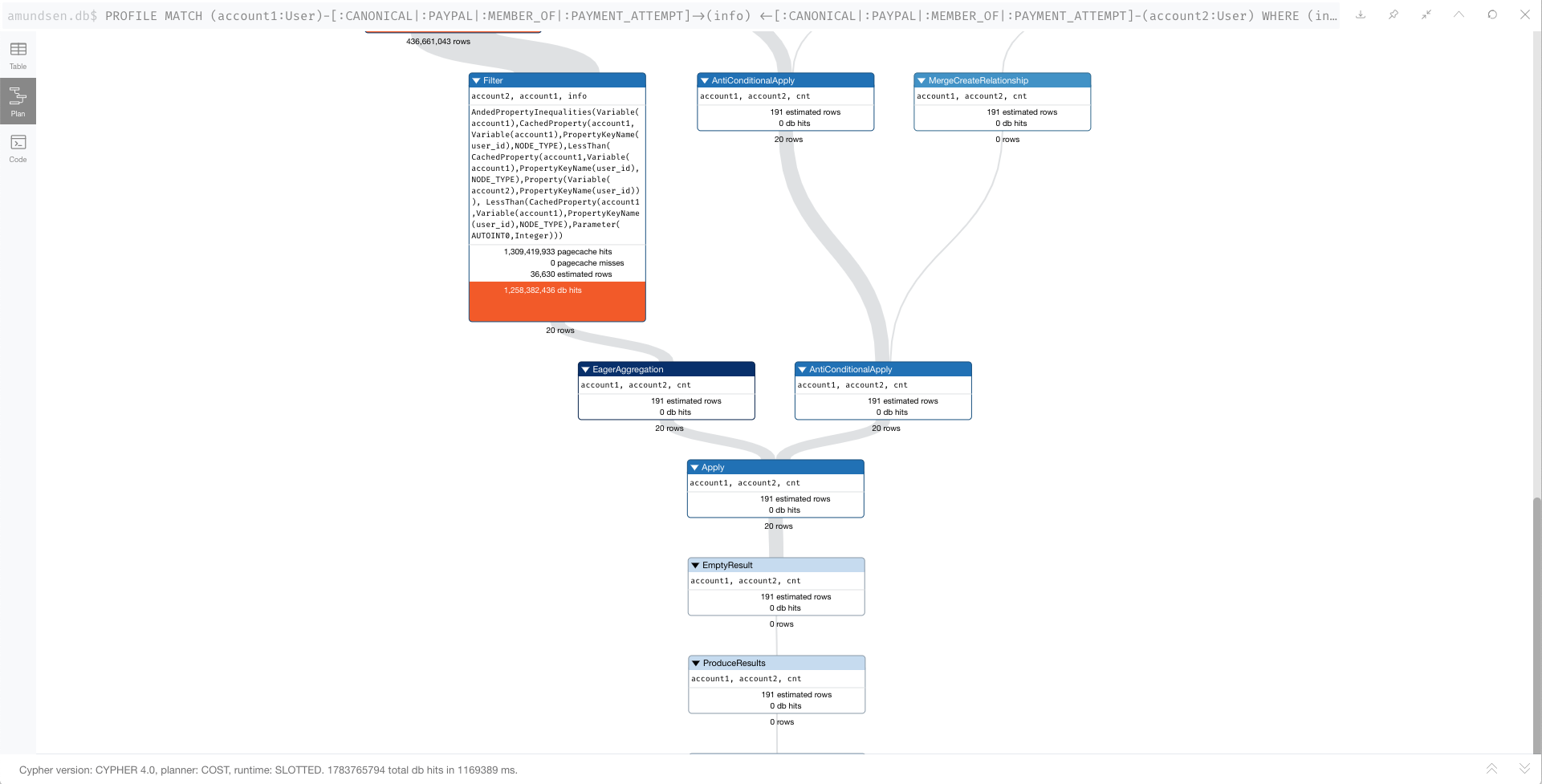
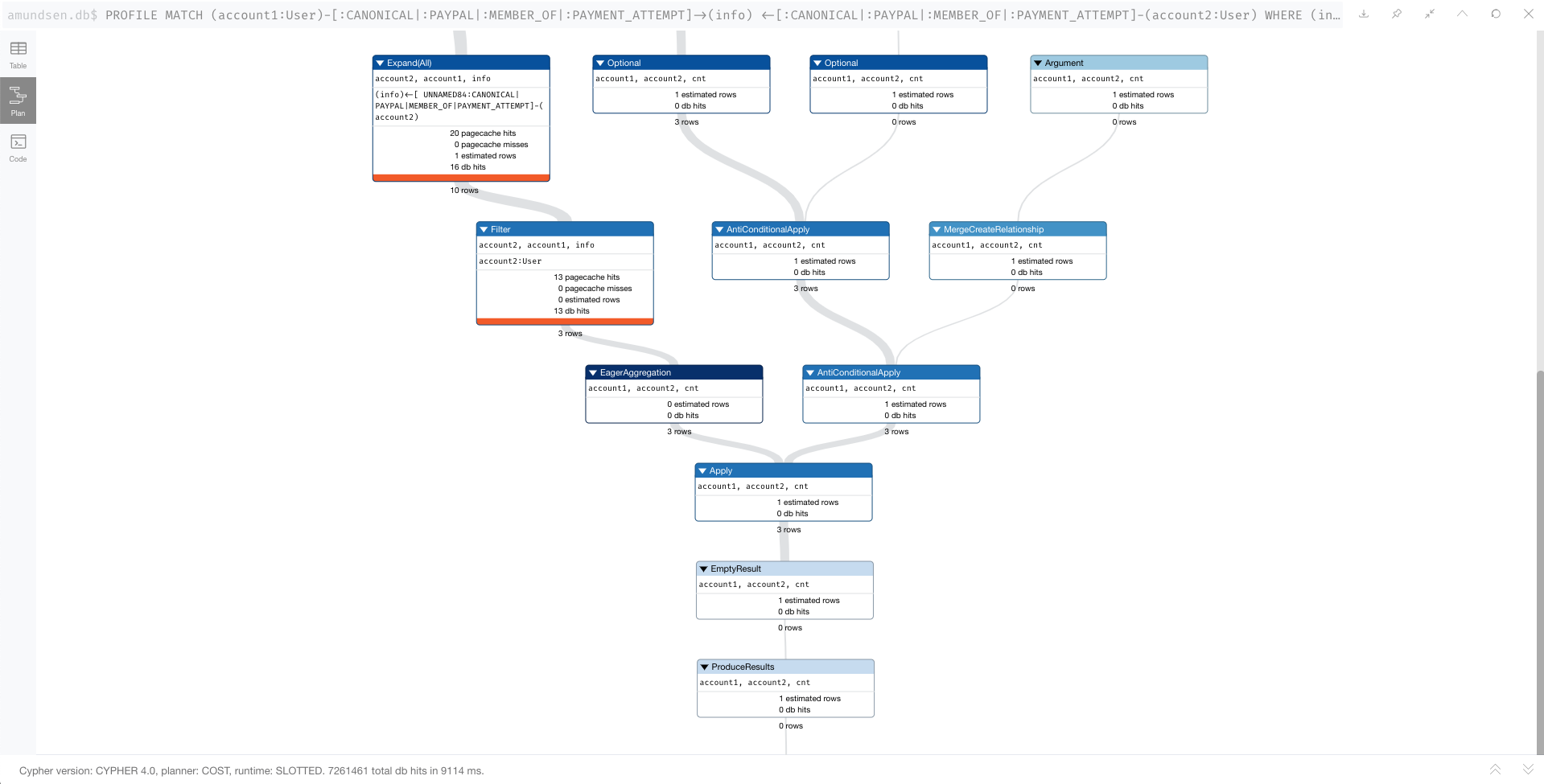
But I think the performance scales super-linearly, as a 2 account query took around 10 seconds. Here is the query and profile for a batch size of 2. This profile also confuses me because it starts with a NodeIndexScan, when I would hope for a NodeUniqueIndexSeek, since I'm specifying two unique user_ids:
Here is the profile:

My naive hope of how the query would run is something like this:
- Resolve the (account1) nodes for the current batch, using the unique constraint defined on User.user_id.
- Traverse relationships to the (info) nodes, facilitated by the native graph processing that keeps relationships close to their nodes.
- Traverse relationships to the (account2) nodes, again using native graph processing.
This seems like it would keep the working set of nodes and relationships small. Both should be less than 100 for a batch of the first seven accounts. But, as shown in the PROFILE, the engine is loading relationships first, then account2, both of which are unbounded sets for the query. The number of rows ends up in the billions. I should note that all Node labels have an associated unique index.
My problem has some things in common with this earlier post:
I think I could update these relationships as nodes are added over time using the advice from that post, but I need to first calculate the initial relationships.
I also found this blog post, thinking that the query replanning might be a factor, but once I narrowed it down to a single query being slow, discussion of batching seems less important:
I explored a little bit of pre-processing, first identifying shared nodes and introducing a :SharedEmail label, for example. Then this query can consider a smaller group of nodes.
I was hoping there might be something else I'm missing here? Cypher allows me to express this query much more clearly than SQL did, but the processing doesn't seem different so far.