Hi All,
Neo4j version 3.4.1 community
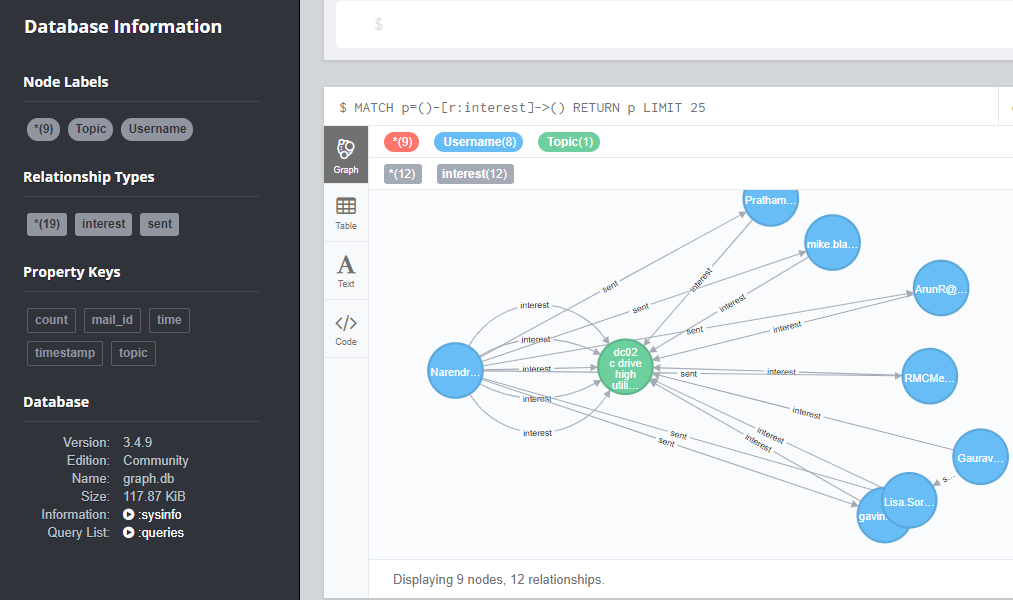
I am tring to build the graph to find the most connected user for this specific topic and below is the simple query I have tried to find the user,
MATCH (p1:Username)-[:interest]->(p3:Topic)<-[:interest]-(p2:Username) WHERE(p3.topic STARTS WITH 'dc02 c drive high utilization')
RETURN *
Query response,

Below is the sample I have indexed it,
date_time,keywords,message_subject,recipient_address,sender_address
2018-09-10T17:36:48.823Z,dc02 c drive high utilization,PDX-VWIN-DC02 C drive High utilization,gavin.debeer@test.com,NarendraChoudaryB@test.com
2018-09-10T17:37:48.823Z,dc02 c drive high utilization,PDX-VWIN-DC02 C drive High utilization,Lisa.Sorenson@test.com,NarendraChoudaryB@test.com
2018-09-10T17:38:48.823Z,dc02 c drive high utilization,PDX-VWIN-DC02 C drive High utilization,PrathamK@test.com,NarendraChoudaryB@test.com
2018-09-10T17:39:48.823Z,dc02 c drive high utilization,PDX-VWIN-DC02 C drive High utilization,ArunR@test.com,NarendraChoudaryB@test.com
2018-09-10T17:40:48.823Z,dc02 c drive high utilization,PDX-VWIN-DC02 C drive High utilization,RMCTeam@test.com,NarendraChoudaryB@test.com
2018-09-10T17:41:48.823Z,dc02 c drive high utilization,PDX-VWIN-DC02 C drive High utilization,mike.blasberg@test.com,NarendraChoudaryB@test.com
2018-09-10T17:51:06.798Z,dc02 c drive high utilization,RE: PDX-VWIN-DC02 C drive High utilization,Lisa.Sorenson@test.com,GauravSi1@test.com
If you check the data in the sender address the user "Narendra" has sent mail to different users for 6 times but in the graph the relationship "interest' is showing only 5 times.
I would like to know why it is showing like that? Please correct me if I am doing anything wrong.
Regards,
Ganeshbabu R