Hello guys. I'm very novice to the Neo4J database.
I'm working in the upload of a halth service upload, to understand common situations between patients, hospitals, doctors and etc.
About my Neo4J Modelling, question:
Age: Patients changes its age, of course, depeding the time which they ask for a service. So, John may be 25 years old 3 years ago and currently 28.
Living City: Patient may change your home and city in any moment of database time.
Both questions associated with the moment of service. What I considere here: I have a situation in booth cases of many to many: many patients may live in many cities.
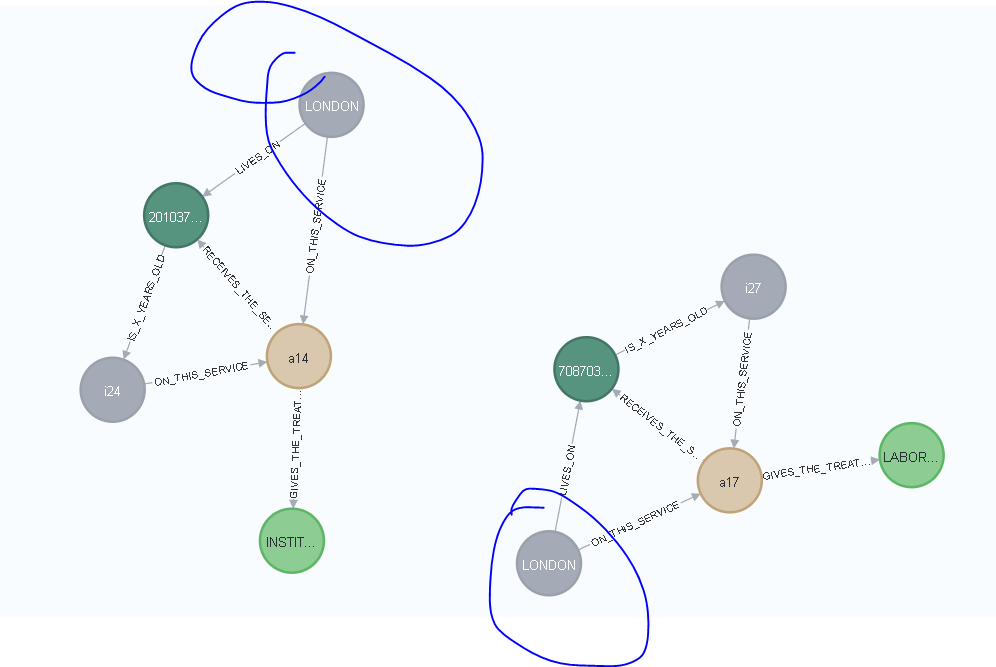
One example of my data, below: I enforced all patients to live in london. Look as we have one node city (LONDON), for each patient, of course, because I associated the living city of that patient with service code.
What is wrong here?
The association is wrong? Should I have a relationsheep similar to a primary key? One patient just could have one living city and is just a single age?
Or m'I missing some code (remember, I'm a novice), to group by this nodes?
If you are uploading from a csv/json - you should use MERGE rather than CREATE, also making sure that the properties are the same in both rows (or at least the identifier/key).
though a patients age changes, their date of birth remains contant. and cant one then just calculate age based upon <date of service/procedure> - < patient data of birth >
Imagine you are INSERTING in a SQL table - without keys ...
So it looks like the first CREATE should be a MERGE AND you don't need the first bit str(cidade_paciente) (that defines a variable that you are not using, just like the c or a in the MATCH later on.
If you still have duplicates, that means that one of the other attributes is different between the creations, as the merge works on merging EVERY attribute present, when you research how to load parameters to queries in python, you can create queries like this:
MERGE (v:cidadePaciente { cidade: $id }) // <- this is the key to merge (cidade_paciente)
ON CREATE // <- if you are INSERTING
SET v.created = timestamp(),
v.updated = timestamp(),
v += $properties // <- this valueData.properties has the properties
ON MATCH // <- if you are UPDATING
SET v.updated = timestamp(),
v += $properties // <- if you have new values
I think my error is that the booth nodes has the same name, but, diferent properties, first is associated to service_id = a1, second, service_id = a16, and diferente patient codes too. I'm doing a relation as multiple for multiple and what seems is that should be like a primary key. Is that correct?
What you see on your browser is not the "node name" ... it is your choice of caption, if you click on the righthand side on a node - you'll get a little popup to change the colour/size and caption:
You are correct on your error - you have a "denormalised" row, but you can separate it by doing something like (pseudocode):
MERGE (C:City {city_code: city_value}) // cities are unique
ON CREATE ... C += <all other city properties>
MERGE (P:Patient {patient_id: id_value} ). // patients are unique
ON CREATE ... P += <all other patient properties>
WITH C, P
CREATE (P)-[R:attended {service_id, and any other properties}]->(C); // if you want them duplicate ... or MERGE if you want them unique
I am assuming service_id is relevant to the "attended" relationship rather than part of either the patient or the city.
Thanks again for your support. I think I've arrived in a good point, regarding codes and modeling. I adjusted booth, using merde and changed the mind set of modeling.
The question now is about ETL time, look my insert code.:
The process is working, the data is being sent to neo4j, however, it is very, very slow. Line per line. Pythong is consuming few resources of my machine: 15% more or less. It is not being a massive ETL process.
Booth are in local machine.
SQL code is the database where I read the data and neo4j where I insert data.
When I run the select from SQL the cpu usage gets close to 100%, in this case, SQL running the select to give the data to Python.
After of Python code gets the data from SQL, the cpu usage slow down to 10%~15%. I understand that Python is not using full resources of my cpu, to input the data in neo4j.
I looked for this question and found I could make a multi threading process, with the code below:
global q
q = queue.LifoQueue()
for i in range(16):
t = threading.Thread(target=script)
t.daemon = True
t.start()
q.join()
In the begining of process, it uses large amount of cpu, but after 10 minutos, as I said, the process slows down and I could not upload all my nodes to neo4j database.
Hello Josh.
Sorry by absence. I had to work in other projects.
Yes, it is public data. Its brazilian public health system. The problem here is that there a lot of treatments before it becames "usable" and "normalized", which I do in an ETL treatment.
By the way, I'm in the same point than before. Uploading the data, which the process I showed you, is a very slow process.
Do you have any advice to give me, regarding this?
Thanks a lot.