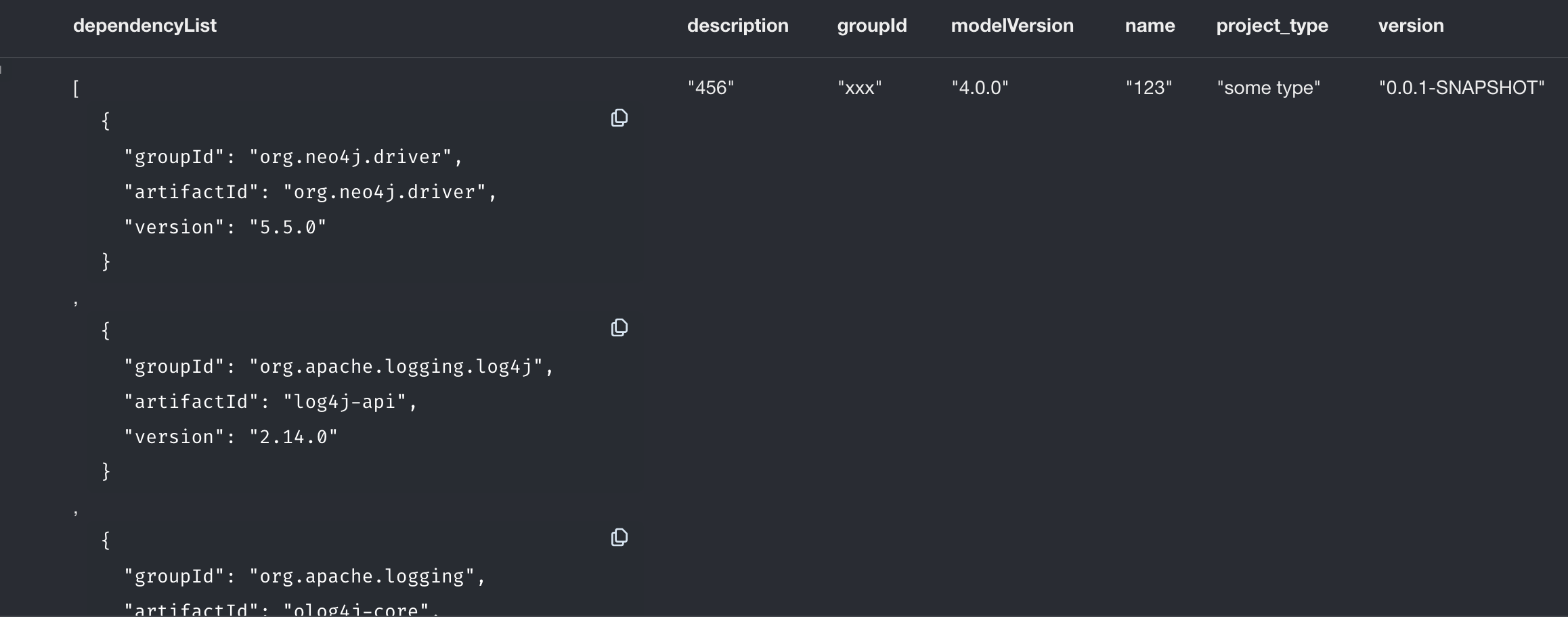
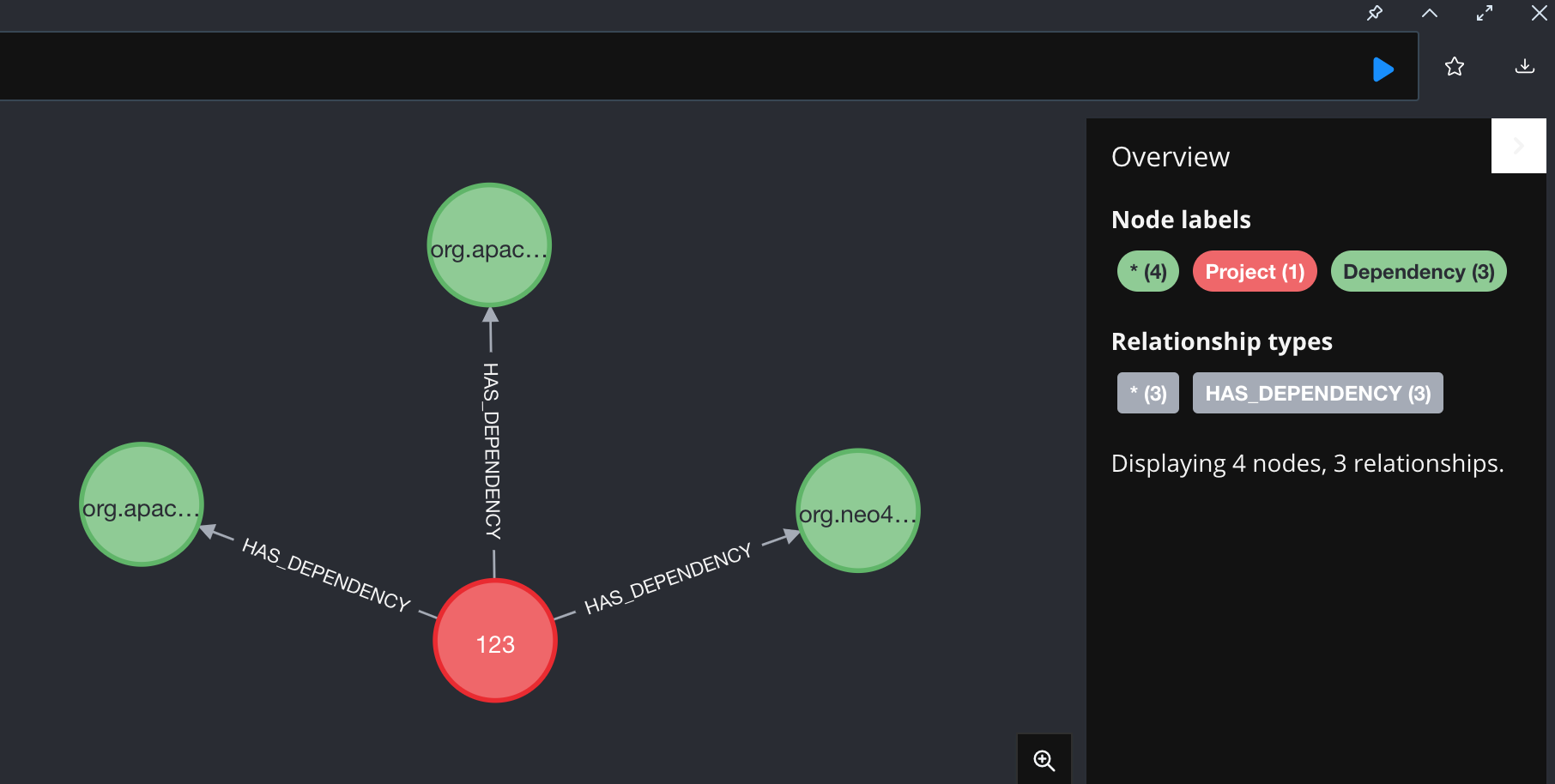
Here is the json 'value' returned from the parser method.
{
"_children": [
{
"_type": "modelVersion",
"_text": "4.0.0"
},
{
"_type": "groupId",
"_text": "xxx"
},
{
"_type": "version",
"_text": "0.0.1-SNAPSHOT"
},
{
"_type": "name",
"_text": "123"
},
{
"_type": "description",
"_text": "456"
},
{
"_children": [
{
"_children": [
{
"_type": "groupId",
"_text": "org.neo4j.driver"
},
{
"_type": "artifactId",
"_text": "org.neo4j.driver"
},
{
"_type": "version",
"_text": "5.5.0"
}
],
"_type": "dependency"
},
{
"_children": [
{
"_type": "groupId",
"_text": "org.apache.logging.log4j"
},
{
"_type": "artifactId",
"_text": "log4j-api"
},
{
"_type": "version",
"_text": "2.14.0"
}
],
"_type": "dependency"
},
{
"_children": [
{
"_type": "groupId",
"_text": "org.apache.logging"
},
{
"_type": "artifactId",
"_text": "olog4j-core"
},
{
"_type": "version",
"_text": "2.14.0"
}
],
"_type": "dependency"
}
],
"_type": "dependencies"
}
],
"_type": "project",
"type": "some type"
}
The first key from the root is '_children'. It is an array of json objects. The first five elements contain the modelVersion, groupId, version, name, and description values. The sixth element is a json object with key/value pairs '_type:dependencies' and '_children', which is another array of json objects that have the dependency information.
To get the dependencies array, we need to get the element from the top-level '_children' array that has key/value pair '_type:dependencies'. This is done with the following expression. It loops through the elements of the value._children array looking for the json object that has its '_type' key equal to 'dependencies'. It then returns only the '_children' element of the json object. There is only one 'type' key with value 'dependency', so the result of the list comprehension will be a list with one element, thus, we get the zeroth element.
[i in value._children where i._type = 'dependencies'|i._children][0]
{
"_children": [
{
"_type": "groupId",
"_text": "org.neo4j.driver"
},
{
"_type": "artifactId",
"_text": "org.neo4j.driver"
},
{
"_type": "version",
"_text": "5.5.0"
}
],
"_type": "dependency"
},
{
"_children": [
{
"_type": "groupId",
"_text": "org.apache.logging.log4j"
},
{
"_type": "artifactId",
"_text": "log4j-api"
},
{
"_type": "version",
"_text": "2.14.0"
}
],
"_type": "dependency"
},
{
"_children": [
{
"_type": "groupId",
"_text": "org.apache.logging"
},
{
"_type": "artifactId",
"_text": "olog4j-core"
},
{
"_type": "version",
"_text": "2.14.0"
}
],
"_type": "dependency"
}
The above result is itself a json array of json objects with a '_children' key whose value is the array of dependency data and a '_type key with value '_dependency'. This is the dependency data we are seeking. To extract the '_children' objects into a list, the expression now iterates through the data shown below and returns just the '_children' values. The final result of this expression is a list of the dependency objects:
[[
{
"_type": "groupId",
"_text": "org.neo4j.driver"
}
,
{
"_type": "artifactId",
"_text": "org.neo4j.driver"
}
,
{
"_type": "version",
"_text": "5.5.0"
}
], [
{
"_type": "groupId",
"_text": "org.apache.logging.log4j"
}
,
{
"_type": "artifactId",
"_text": "log4j-api"
}
,
{
"_type": "version",
"_text": "2.14.0"
}
], [
{
"_type": "groupId",
"_text": "org.apache.logging"
}
,
{
"_type": "artifactId",
"_text": "olog4j-core"
}
,
{
"_type": "version",
"_text": "2.14.0"
}
]]
The following expression in the next line, extracts the dependency data into a list of maps, where 'dependencies' is the variable representing the data above.
[i in dependencies | {
groupId: [x in i where x._type = 'groupId'|x._text][0],
artifactId: [x in i where x._type = 'artifactId'|x._text][0],
version: [x in i where x._type = 'version'|x._text][0]
}]