I am importing several datasets of which a couple of large ones (500K-1.5M documents of the type shown below), and I have an index created with the command
"CREATE CONSTRAINT ON (n:_) ASSERT n.id IS UNIQUE;"
Indexing time goes from a couple of ms per document at the beginning to currently 1s per document (import still running).
Is this normal? How can this be prevented?
- neo4j version, desktop version, browser version
3.3.0 Community - what kind of API / driver do you use
http /db/data/transaction/commit - screenshot of
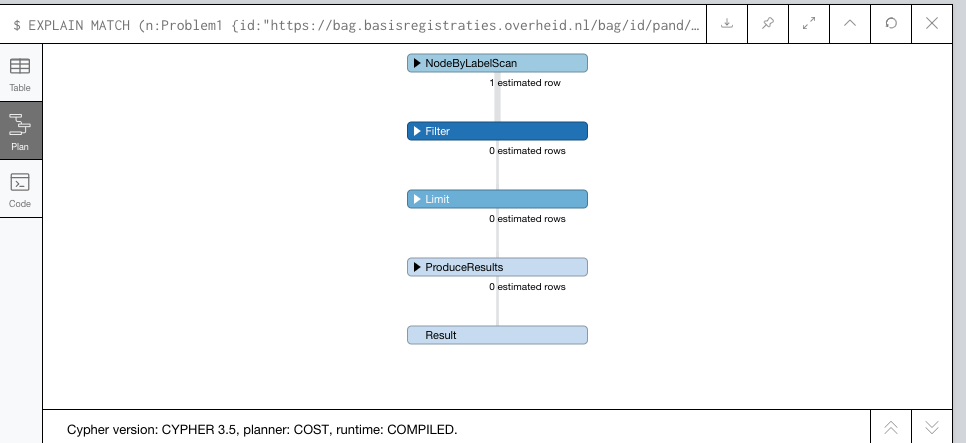
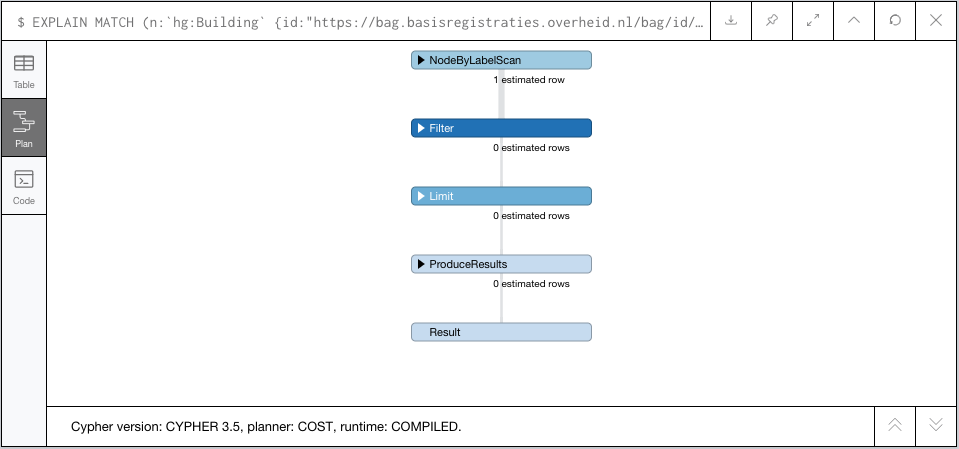
PROFILEorEXPLAINwith boxes expanded (lower right corner) - a sample of the data you want to import
"parameters": {
"operation": "add",
"dataset": "bag",
"type": "hg:Building",
"id": "https://bag.basisregistraties.overheid.nl/bag/id/pand/0082100000158084",
"data": {
"uri": "https://bag.basisregistraties.overheid.nl/bag/id/pand/0082100000158084",
"type": "hg:Building",
"validSince": [
"1977-01-01",
"1977-12-31"
],
"geometry": "{\\"type\\":\\"Polygon\\",\\"coordinates\\":[[[5.70891547486678,52.8504181579206],[5.70891457428957,52.8504168123607],[5.70894999504419,52.8504089883029],[5.70896652550447,52.8504363528222],[5.70900994956621,52.8504267996935],[5.70906180219923,52.8505135601466],[5.70903749603102,52.8505188379876],[5.70903433968836,52.8505135444138],[5.70898068889875,52.850525281936],[5.70896446255978,52.8504989051244],[5.70896638900196,52.8504984505955],[5.70893317961297,52.8504437219559],[5.70893125317285,52.8504441764843],[5.70891547486678,52.8504181579206]]]}",
"dataset": "bag",
"validSinceTimestamp": 220924800
},
"structure": "node"
},
"statement": "MERGE (n:_ {id: {id}})\\nON CREATE\\n SET n = {data},\\n n.created = timestamp(),\\n n.id = {id},\\n n.dataset = {dataset},\\n n:`hg:Building`\\nON MATCH\\n SET n = {data},\\n n.accessTime = timestamp(),\\n n.counter = coalesce(n.counter, 0) + 1,\\n n.id = {id},\\n n.dataset = {dataset},\\n n:`hg:Building`\\n REMOVE n:_VACANT\\nRETURN n\\n"
},
- which plugins / extensions / procedures do you use
- neo4j.log and debug.log