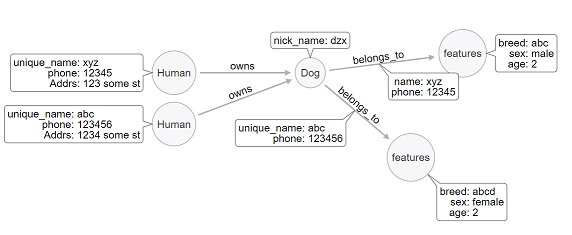
The Dogs' nicknames are unique per Human and I can find the Human by his/her unique_name. But it is quite common to have a lot of dogs with the same nickname.
Thinking about performance, the "faster" way is to start with the Human and then find the Dog, but should I consider adding and index on Dogs' nickname to give a second option fot the Neo4j?
Does it help somehow with the performance?
It seems to me that it would help if I have a uncommon nickname, but in my case I know that there will be at most 5 nicknames, but there is no known limit to how many Humans' names will be present.
Can someone explain me how to proper think about this?
Here you can get dog's name for each person or get all persons who owns a dog with a particular nickname.
2: Create an index on on dog's nickname. Here to correctly identify the dog a person we must add more info about the dog a person owns. Here is how it looks:
A perfect match between person and dog, it would be better to have phone number or street address (unique to a person) and we can use this with features node as shown above.
MATCH (h:Human)-->(d:Dog)-[r]->(f:feature) WHERE h.unique_name = "xyz" and r.name = "xyz"
The query returns the correct dog "xyz" owns.
MATCH (h:Human)-->(d:Dog)-[r]->(f:feature) WHERE h.unique_name = "abc" and r.name = "abc"
The query returns the correct dog "abc" owns.
@guilherme.junqueira It really depends upon the types of queries you plan to run, and what parameters are provided to the query.
If you're trying to find all humans who own dogs of a certain nickname, then an index on the dog's nickname makes sense. If you're trying to find all dogs owned by humans by a unique names, than an index (or rather a unique constraint in this case) on the human's name makes sense.
If you're providing both the human's name and the dog's name to the query, then the query planner has the option of selecting either one, and it will attempt to use statistics it knows about your data to choose a fast starting point. You would have to PROFILE the query to see if it's selecting a good plan, and you can check how other plans perform by using index hints, which will force the planner to choose certain nodes for index lookup.
To summarize, the queries you plan to run should drive the indexes you think would be most beneficial, and when multiple starting places are present for index lookup you should run your own profiling to verify that good plans are being selected, and if not adjust your query with index hints.
What would you consider the cons of creating the indexes on those properties beforehand if I don't exactly know what would be the future queries on this database?
It feels to me to be the "safer" approach and the only con I can thing of is bigger storage usage.
As you say, storage would need to be set aside for the additional indexes, and of course when indexes are present there will be a penalty to write operations of nodes of that type as indexes will need to be transactionally updated.
As far as composite indexes, the ordering does not matter, there is no need to create multiple indexes in a different order (I'd hope it wouldn't let you in the first place). Keep in mind that a composite index will only be used if both properties are provided in the match...it is not a substitute for two separate single-property indexes.
I am aware that a composite index is not a substitute for two single-property indexes, but it is always good to reiterate this!
As far as the ordering of composite indexes, if Neo4j is similar to other database engines, it does matter because you never know which of properties have a better selectivity than the others.
Confirming my suspicion, I just run :schema here and found:
ON :Election(year, auto_name) ONLINE (for uniqueness constraint)
ON :Election(auto_name, year) ONLINE
So this brings me back to my original question: how Neo4j choose which one of the indexes will be used?
Thanks in advance,
** auto_name is just standardized string that identifies each Election together with the related year.
I would say this is a bug that both can be present at the same time, I'll raise that with our engineers. In any case this should not be in the graph.
For composite indexes, the combination of properties in the index drives the lookup. It's not as if one index is applied and then the other filters.
For two single-property indexes on the same node, however, the query planner uses metadata it knows about your graph (from the index and from the counts store) to make a choice on which index to use. As mentioned above, if you find that the choice is not optimal in the cases you need, you can always supply an index hint to the planner.
I don't consider the existence of two composite indexes over the same properties in different orders as a bug.
They will eventually lead me to the same "data" at the end, but the efficiency of them can be huge. Obviously I don't have much knowledge in Neo4j itself, but I am bringing here the knowledge I have with different databases engines.
One way to understand this is think about the ordering of row in Excel. The order of the properties in the composite index relates pretty well to the order we sort a spreadsheet by multiple columns.
Perhaps it might be easiest to say that the ordering of properties in the composite index should have little effect on how the composite index is formed, and no effect on performance of index lookup. Composite indexes are not groupings of separate lookup and filtering operations. Instead the combination of the multiple values is itself indexed.
Therefore the performance of index lookup between two separate composite indexes in different orders should be identical, the ordering should not matter.
I will double check with our engineers just in case.
I beg to differ, though. Suppose I have nodes with two properties as the following and two composite index: index1 (A, B) and index2 (B, A):
A B
------
a 1
a 2
a 3
a 4
a 5
b 1
b 7
b 8
b 9
b 10
If I search for the value (b, 7) and Neo4j chooses index1, it excludes 50% of the possible "rows" on the first level and then finds 7 in 20% (1 row out of 5) within the remaining.
If it searches with the other index, it excludes 90% of the rows and finds b in directly because there is only 1 row left.
I am using small sets here just exercise "my logic", but imagine if the pairs (A,B) are no unique and there are multiple "rows" that fit my search criterium. I would definitely have a performance penalty in my opinion...
@guilherme.junqueira You are right in that the order would matter a lot in some cases. For example when you query for a specific range, let's say range a-b and exact match on 1 in your example, [a-b, 1].
Here you want to use index2 (B,A) because searching for 1 gives much more narrow hit and you'll end up searching through a smaller sub-range.
If you use index1 (A,B) you will end up looking at every single value and filter away non-hits.
This is also why it is allowed to create two composite indexes on the same properties but in different order.
However, currently Neo4j only support exact match and full scan on composite indexes and in those cases the order does not matter. And this is where @andrew_bowman is correct.