Hello guys,
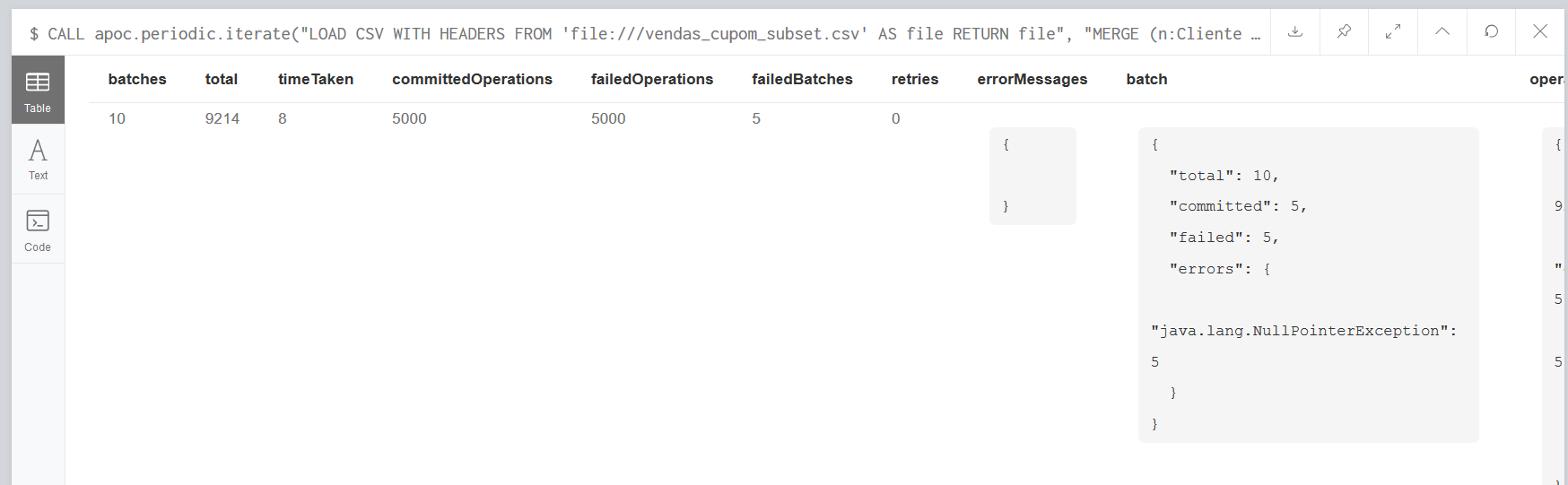
I'm using the apoc.periodic.iterate to create a graph from a csv file containing 10k rows (to start off), but I think it's taking longer than it should to finish the command (around 50 seconds). Here is how the entire command looks like and the image of the results:
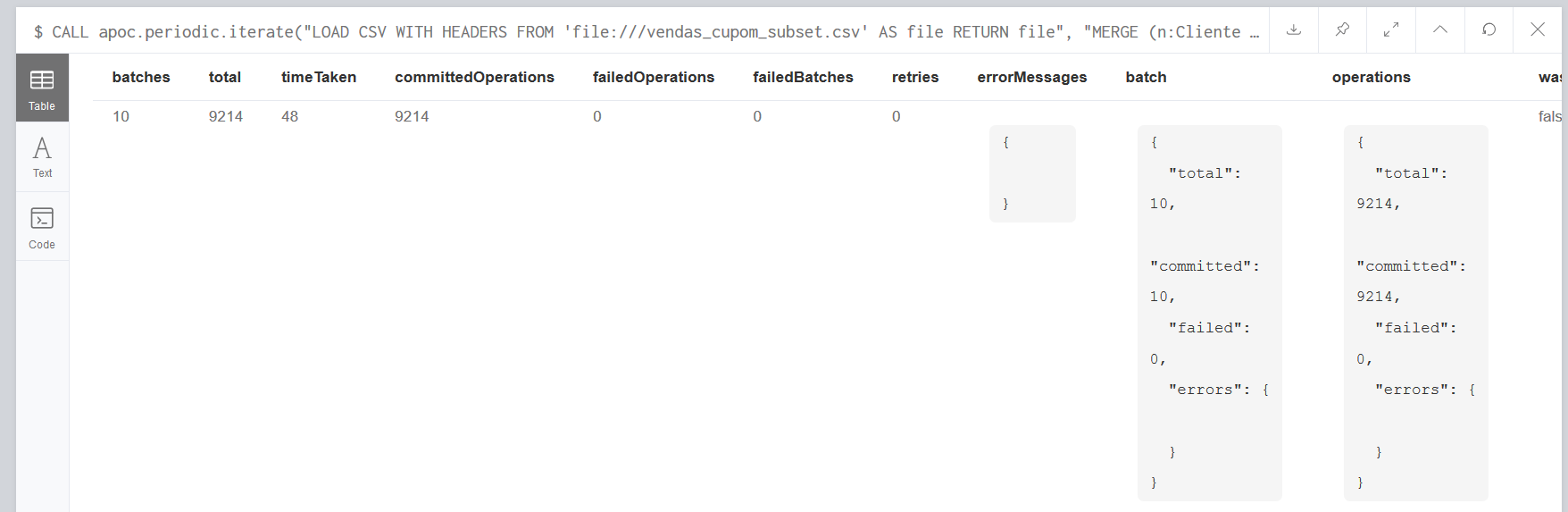
CALL apoc.periodic.iterate("LOAD CSV WITH HEADERS FROM 'file:///vendas_cupom_subset.csv' AS file RETURN file",
"MERGE (n:Cliente {cpf: file.CPF}) MERGE (m:Cupom {codigoCupom: file.NUMEROUNICOCUPOM}) MERGE (o:Produto {codigoProduto: file.CODIGOPRODUTO}) MERGE (p:Filial {codigoFilial:file.CODIGOFILIAL}) MERGE (n)-[:FEZ_PEDIDO {dataMovimento: file.DATAMOVIMENTO}]->(m) MERGE (m)-[:CONTEM {qtd:file.QTD_PRODUTO}]->(o) MERGE (o)-[:VENDIDO]->(p)",
{batchSize: 1000, iterateList:true, parallel: false});
I'm running it on neo4j desktop. My computer is aN i5 vpro 2.50 ghz, 8gb ram and 200 gb ssd. I didn't alter the configurations to increase the heap/ram memory, so it's default. I also tested running the same command on cypher-shell, but the difference was very little. Also tried changing the batchsize to 100 and 10k, but it got worse.
I'm really concerned because I'll have to create the same graph, reading from the same csv containing millions of lines, and it doesn't seem very performatic.
How can I improve my query, having in mind that in the future i'll have to insert millions of registers.?
here's how my csv file looks like:

If I set the parallel parameter 'true', it inserts faster, but with failed operations: