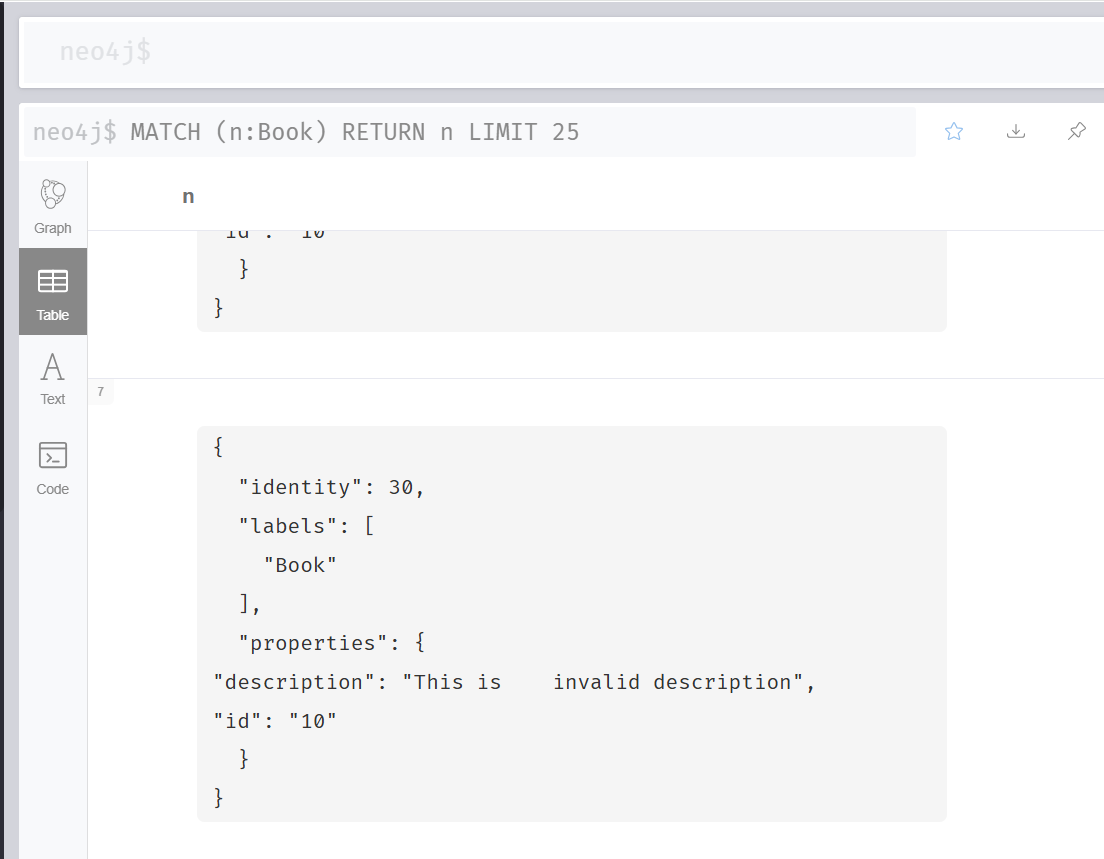
This is my data
{
"identity": 15,
"labels": [
"Book"
],
"properties": {
"description": "This is the book description",
"id": "2"
}
}
{
"identity": 17,
"labels": [
"Book"
],
"properties": {
"description": "This is the description",
"id": "1"
}
}
{
"identity": 19,
"labels": [
"Book"
],
"properties": {
"description": "This is description",
"id": "3"
}
}
{
"identity": 20,
"labels": [
"Book"
],
"properties": {
"description": "description is This is description",
"id": "3"
}
}
{
"identity": 25,
"labels": [
"Book"
],
"properties": {
"description": "This is description",
"id": "4"
}
}
{
"identity": 29,
"labels": [
"Book"
],
"properties": {
"description": "This is description",
"id": "10"
}
}
{
"identity": 30,
"labels": [
"Book"
],
"properties": {
"description": "This is invalid description",
"id": "10"
}
}
This is how i created full text index
-- create full text index
CALL db.index.fulltext.createNodeIndex("book_index_1",["Book"],["description"], { analyzer: "keyword", eventually_consistent: "true" });
This is working.
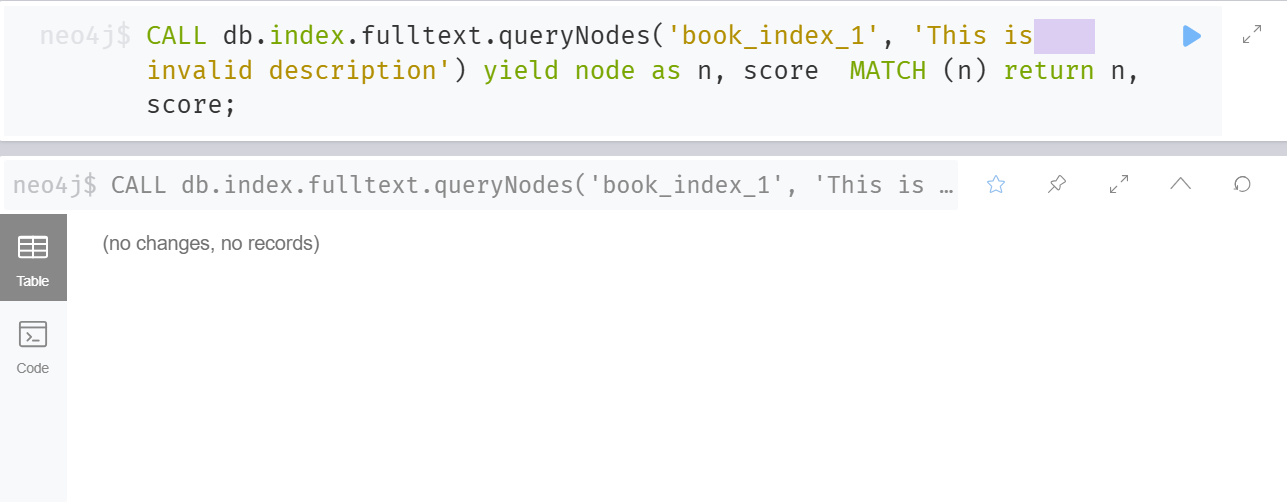
CALL db.index.fulltext.queryNodes('book_index_1', 'This is description') yield node as n, score MATCH (n) return n, score;
This is not working – similar data with space is present.
CALL db.index.fulltext.queryNodes('book_index_1', 'This is SPACE_HERE_AS_IN_DATA invalid description') yield node as n, score MATCH (n) return n, score;
@Ari_Neo4j @dana_canzano