
Hi everyone! I'm new with chyper and I want to find all the closed cicles in a graph, but I want to avoid duplicated loops. So, suppose that 3 nodes A,B,C create a loop. By searching them with "MATCH p=(n)-[*]->(n)
WHERE id(nodes(p)[0]) = id(nodes(p)[-1]) AND length(p) > 1" in the output I have three times the same loop, with of course a different start node. How can I do to return the loop just 1 time, no matter the start node?
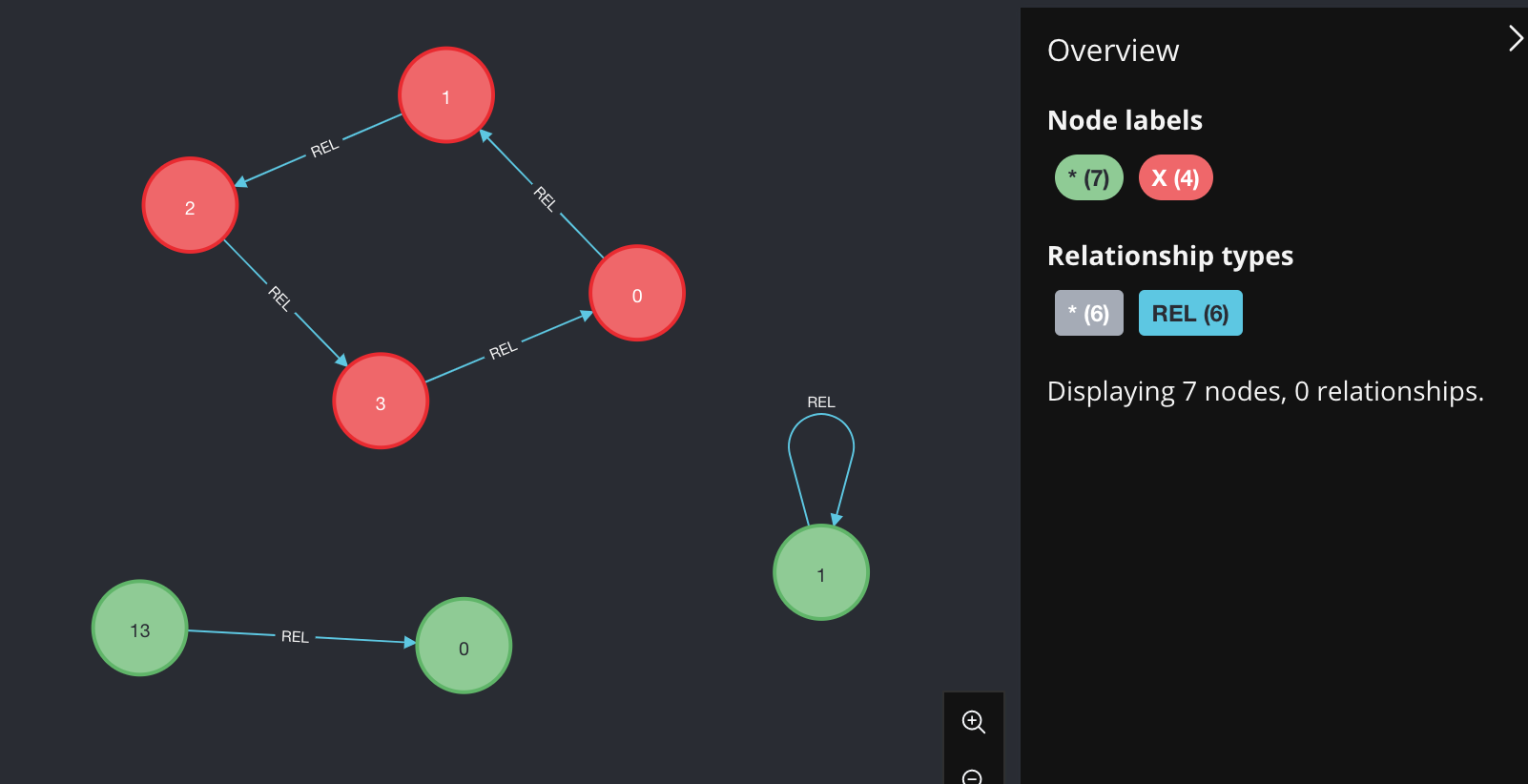
Thank you very much!
If you are in AURA, or on a recent version of Neo4j (>=5.9) you can also use quantified path patterns (QPPs).
// starts and ends on same node, repeat relationships one or more time (+) as long as the pre node has id <= pre node
MATCH path=(n) ( (pre)-[]->(post WHERE id(pre) <= id(post)) )+ ()-[]->(n)
return [i IN nodes(path) | i]
This will return the full loop (the last node is the same as the first node).
I find this more readable (a matter of taste, I guess), but more importantly if you have a big graph, it should be much more efficient. QPPs inline the filtering: they discard unwanted solution while they navigate the graph.
Solutions that use variable length path patterns (the one you are using) usually expand all possible paths and only after that filter out the paths that do not satisfy the filter, using more processing and more memory.
If you want to learn about QPPs, see the Patterns section in the Neo4j Cypher manual.
@valerio.malenchino, I agree with you on the benefit of qualified paths, so I have started to learn the syntax.
From the little I have learned, it doesn’t seem that this query does the same thing? Isn’t it looking for paths where each segment along the path has the condition that its start node’s id is less than the end node’s id? If so, this is much more restrictive and is not necessarily true.
Can you have a qualified path solution where the id of the segment’s beginning node is less than n’s id?
The paths themselves have no characteristic other than the start and end nodes are the same. As such, I think the cypher query has to find each duplicate and then apply some de duplication. I just suggested keeping the paths whose start node had the largest id, as the set of duplicate paths would have an instance for every value of the path’s nodes ids at its starting node.
@valerio.malenchino thank you so much for the new knowledge: unfortunately this query doesn't return all the closed cycles of my graph, but only some of them(the output should contain 22 loops, but it returns only 17 ) . At the same time, you are right about the efficiency because the solution provided by @glilienfield takes too much time for a bigger graph( of 42 nodes and 74 relationships,like the one in the picture ). It works properly only for a small graph.

I think this variation to @valerio.malenchino solution may work:
MATCH (n)
MATCH path=(n) ( (pre)-[]->(post WHERE id(pre) <= id(n)) )+ ()-[]->(n)
return path
with filter:

without filter:
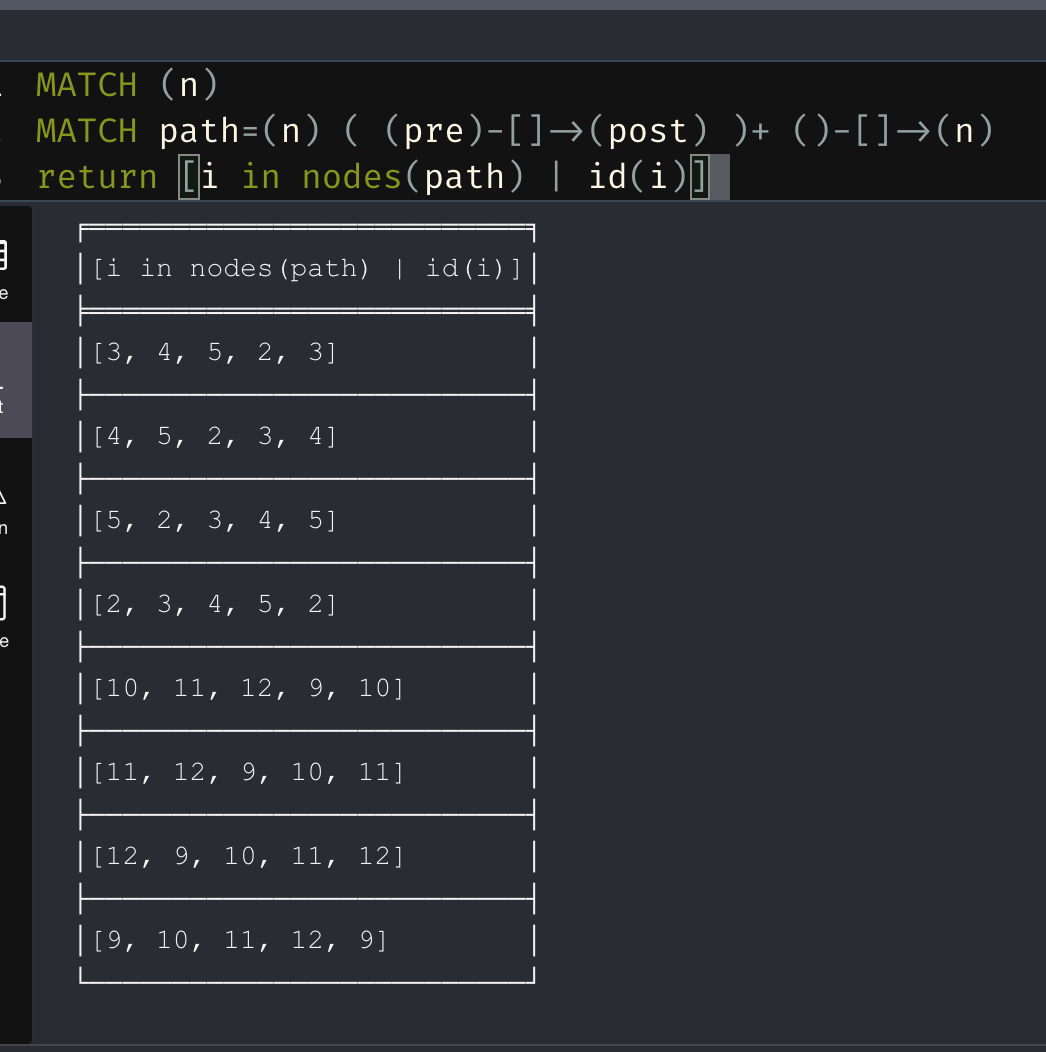
this syntax my be more intuitive. I just moved the 'where' clause out of the node and into the qualified pattern, since it is did not involve the node it was in.
MATCH (n)
MATCH path=(n) ( (pre)-[]->(post) WHERE id(pre) <= id(n) )+ ()-[]->(n)
return [i in nodes(path) | id(i)]


No, I don't want to include self-referencing nodes. I need to return the entire path, so not only the nodes that create the loop, but also the relations between them and by trying the first query( your variation to the solution proposed by @valerio.malenchino ),that returns path, I just discovered a corner case that I ignored so far: a loop inside another loop, and this should be avoided.
An example from the subgraph below is the loop :[1,2,12,34,33,16,17,18,14,15,14,7,8,9,1] where there is the also the loop: [14,15,14]. I need to figure out how to exclude these cases now, I suppose by checking that each single node is visited only once.

Anyway, thank you very much for helping me!
@glilienfield You are right, I misread the original question.
Starting from your modified version and using apoc functions, this might be a way of dealing with nested loops:
MATCH (n)
MATCH path=(n)( (pre)-[]->(post) WHERE id(pre) <= id(n) )+ ()-[]->(n)
WHERE not apoc.coll.containsDuplicates(tail(nodes(path)))
return [i in nodes(path) | id(i)]
This query does post-filtering of paths containing duplicated nodes (inner loops). It uses tail() to exclude the expected duplicated nodes (start/end nodes). Post-filtering should be acceptable if the expectation is that inner loops are corner cases.

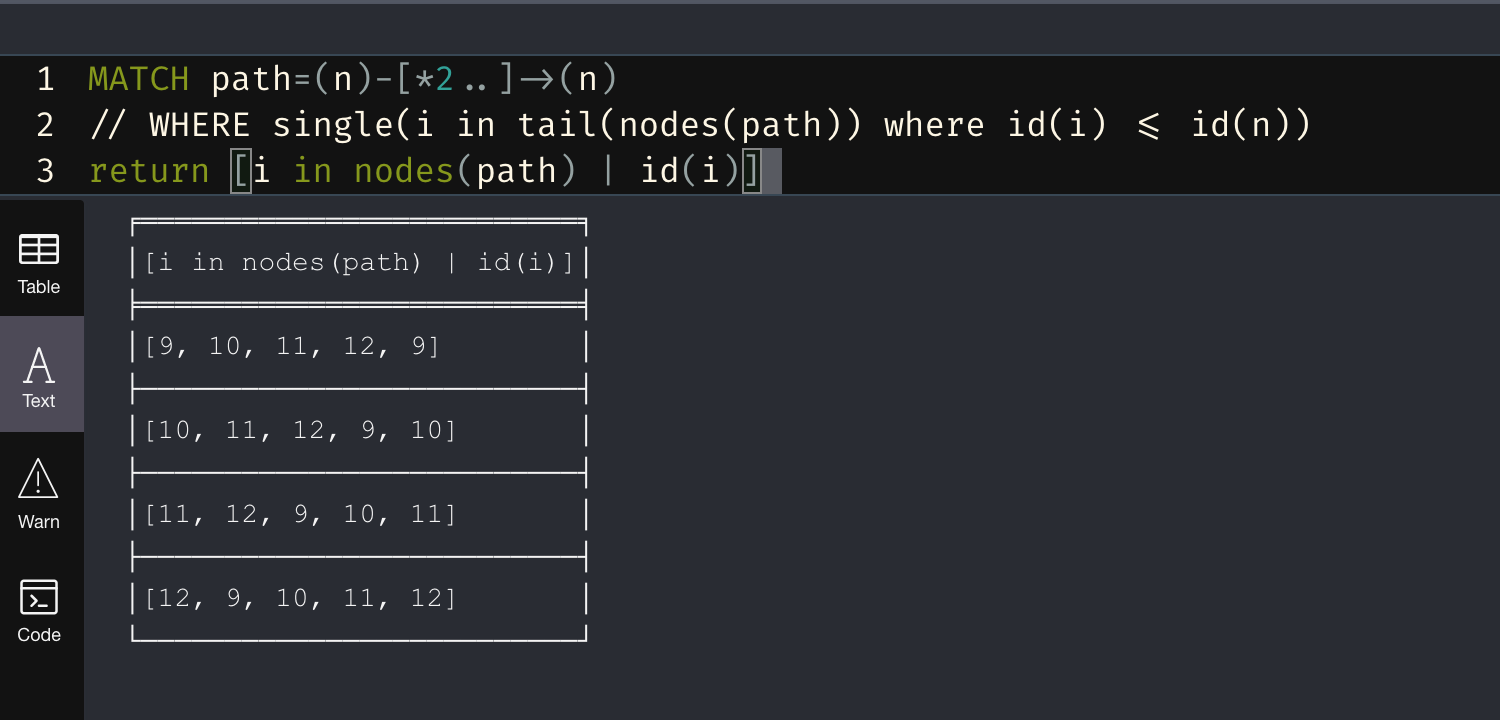
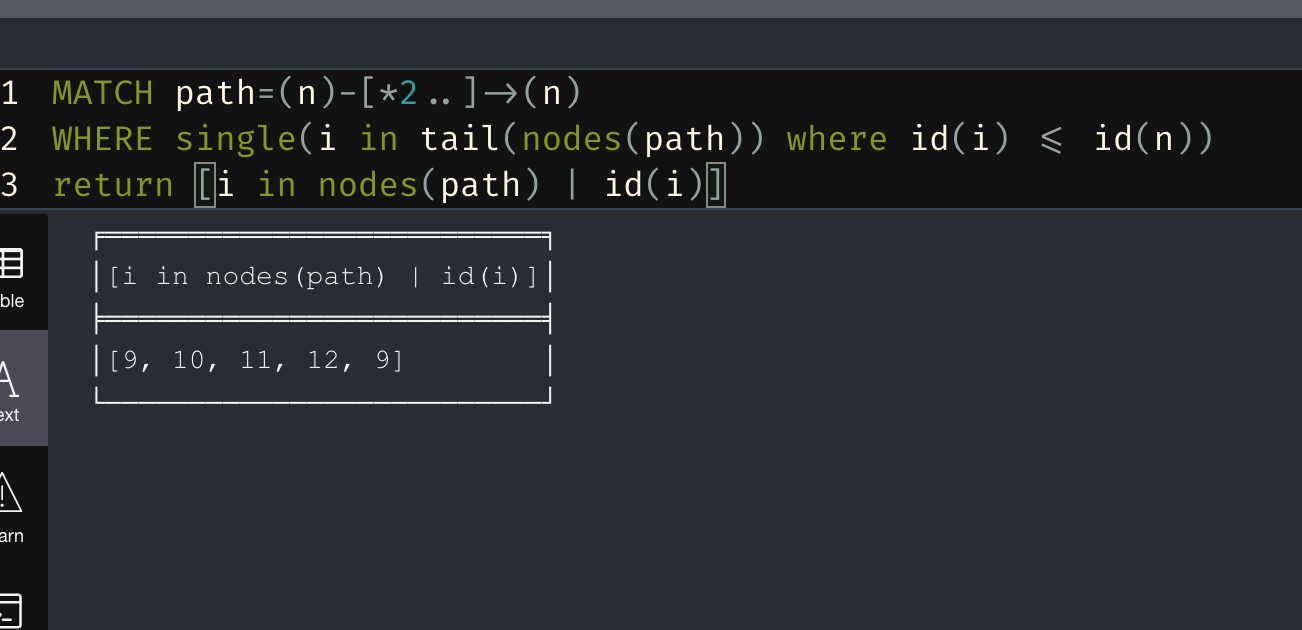
something is off, as the condition is supposed to filter out any paths where the id of the node other than the starting node is not less than the id of the starting node. The 2nd, 3rd, and 6th don't meet this criteria.
Can you provide this test data, is this part of a large existing db?
Sure. It is a small graph composed by 18 nodes and 27 relationships.

Covid-CLD.txt (4.1 KB)
the txt file contains the script to quickly create the graph.
Try
MATCH (n)
MATCH path=(n)( (pre)-[]->(post) WHERE id(pre) <= id(n) AND id(post) <= id(n))+ ()-[]->(n)
return [i in nodes(path) | id(i)]
not all the post become pre in the next round, so in the previous query, the condition does not apply to the penultimate node.