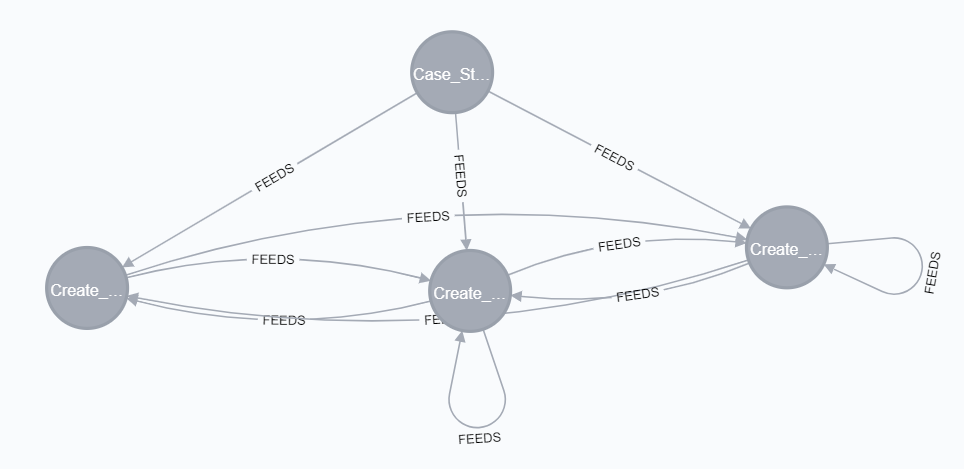
I have a bunch of connected activities (nodes) in CSV format, one file containing the activities, and another the connections. I have no problem creating the nodes, but I just cannot get the links created without duplicates.
Activities/Nodes
ResourceName Min Mode Max
Case_Start 0 0.3 9.8
Create_Delivery 0 0 0
Create_Quotation 0 0 0
Create_Sales_Order_Item 0 0 0
Cypher to create the nodes:
LOAD CSV WITH HEADERS FROM "file:///ACTIVITIES_O2C.csv" AS row
CREATE (a:Activity {Name:row.ResourceName, Min: toFloat(row.Min), Mode: toFloat(row.Mode), Max: toFloat(row.Max), Cost: toFloat(row.CostRate)})
LOAD CSV WITH HEADERS FROM "file:///CONNECTIONS_O2C.csv" AS row
MATCH (lft { Name: row.StartingActivity })
MATCH (rgt { Name: row.EndingActivity })
MERGE (lft)-[r:FEEDS]->(rgt)
SET r.Likelihood = toFloat(row.LinkProbability),
r.Min = toFloat(row.Min),
r.Mode = toFloat(row.Mode),
r.Max = toFloat(row.Max)
The MERGE clause takes the whole statement into account to determine if a match is made. I suspect that as your data loads, there are multiple entries in your connection file that would map a start node to an end node. In the cypher I wrote, it would look up to see if there's already a relationship between the two nodes and if there is, it's going to update the relationship instead of creating a second relationship.
As far as the circular paths, I would validate the source data again. The fact that you're getting multiple relationships between nodes and circular paths, I would double check how the CSVs are being generated.
Thanks Mike, but that doesn't solve the problem. And, no, I do not have duplicates in the data file. If after loading the data I run the Cypher statement
MATCH p=(:Activity [Name: 'Case_Start'])-[r:FEEDS]->() RETURN p