Hi, this is super simple for a non-aura setup using the APOC apoc.export.query function however, that's disabled on Neo4j-Aura due to security reasons (from what I read).
What I need to do:
Export data/sub-graph from Neo4j Aura
Import data to local neo4j
Consider the following graph.
I've tried: match (a {syncLocal: true})-[r *0..1]-(x) return *
Have you tried exporting your Aura database as a stream using these steps? You'll need to use the Neo4j Desktop app and not the Aura browser for your connection, as you need to have access to a local disk to save the stream. But the connection process in the browser inside Desktop is the same as connecting in the browser in Aura. Just provide your Aura connection URI, your database username, and the password for your database and click Connect.
Once you've saved your CSV file you can import it into your local database using LOAD CSV.
I got the same error as with other 'export' apoc functions:
Failed to invoke procedure apoc.export.csv.graph: Caused by: java.lang.RuntimeException: Export to files not enabled, please set apoc.export.file.enabled=true in your neo4j.conf
I did try and change the config with :config 'apoc.export.file.enabled': true but I get the same error.
Thanks Cory! We worked more through support email and it seems that virtual graph doesn't handle this quite well and produces duplicate data.
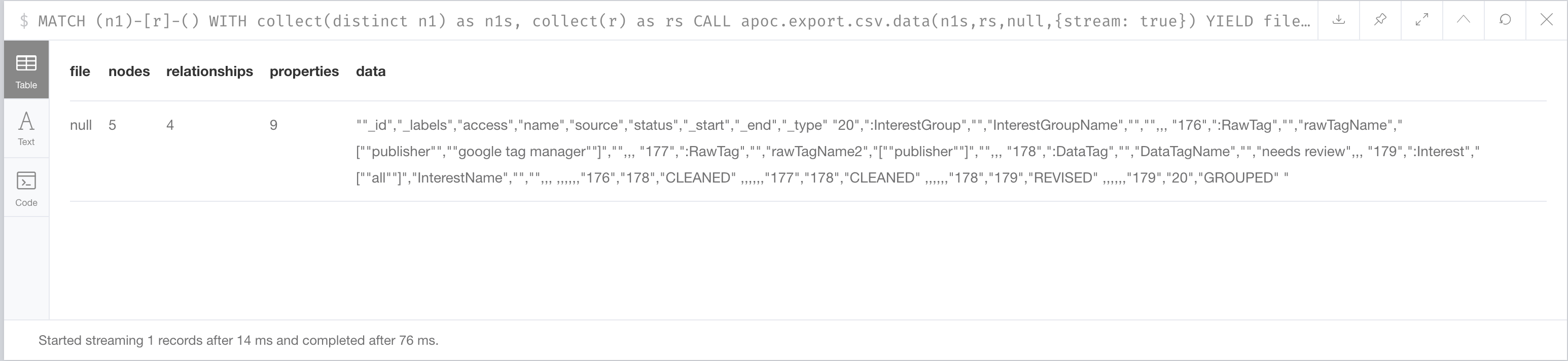
Looks like a got a file out of it now.
So the solution looks like this so far:
MATCH (n1)-[r]-()
WITH collect(distinct n1) as n1s, collect(r) as rs
CALL apoc.export.csv.data(n1s,rs,null,{stream: true})
YIELD file, nodes, relationships, properties, data
RETURN file, nodes, relationships, properties, data
Make sure to have the apoc plugin installed.
I'll report back once I get it to import as well.
We would like to do a similar thing with our Aura cluster, but I got lost trying to follow the logic of this thread:
we can connect to the remote Aura cluster from Neo4j Desktop, by providing the address and credentials
from there, the apoc.export.csv.* functions cannot accept a CSV filename as a parameter, any attempt to do so results in the runtime exception:
Export to files not enabled, please set apoc.export.file.enabled=true in your neo4j.conf
but this isn't possible, there is no local neo4j.conf to edit when connecting to a remote server, and you can't edit the remote server's config
calling apoc.export.csv.* with a null value for the file and including {stream: true} does return data without any errors, but how would you then get that into a CSV (or local graph) for debugging?
To export the data you'll need to download it. Run the query in the browser, then hover over the icon in the upper right corner that looks like an arrow pointing down at a line. You'll get a menu to choose Export to CSV or Export to JSON. Either one will download a file you can then use locally.
See the two screenshots below. The first shows the output of running the query, the second details the highlighting when you hover over the icon.
Thanks Cory. I guess returning the data and exporting it to CSV as a second step means there is a relative ceiling on how much data can be copied in this way e.g feeding in (n)-[r]-(n) from a large graph is unlikely to scale well?
There is, though I'm not sure where the ceiling lays. I've successfully done this with graphs with thousands of nodes; anything more than that, and you'd probably want to add in LIMIT and SKIP calls to break up the work (as one example, there are other ways to skin that cat).
Hi @cory.waddingham What's the most practical way to export all the data from Aura and import it into Neo4j Enterprise (local)? I've found using Aura is very limited because there's no manual or point in time backup capability - or am I wrong? It means there's no way to test stuff. Please help ?
We can export a dump of your database and make it available to you, that's definitely the easiest way to move your Aura database to an enterprise cluster.
There isn't currently a way to purposefully run a backup, nor is there a point in time recovery per se. But there is a way you can get the same end results.
Every time an Aura database is resized, the system automatically starts a backup. So if you were to resize your database to the next size up, it would trigger a backup. Once the resize is complete, you can resize to the previous size to avoid costly increases in your usage (you'd only have to pay for the few minutes between when each resize operation was successful). You'd then have a backup available from the time of the resizes that you could restore into your database and restart your testing.
Incidentally, the dump download option can also be used to copy your data to a new Aura database. In case you want copies of the data for dev and testing. While it's currently a manual process our engineers are working on automating it.
If you'd like to make use of the dump option please open a ticket at https://aura.support.neo4j.com and let us know the URI of the database in question. I or one of my colleagues will assist you.
Thanks @cory.waddingham. Can you advise when the backup process for dump will be automated so we can do it ourselves? I can imagine the support process is not instant so limiting when you have a process you are running through.
We don't have a release date scheduled yet so I can't say for certain. But the support team is ready to make the dump available for download whenever you'd like. Just let us know by opening a ticket in our support portal. We can give more private instructions for downloading it there once it's been created.
I'd like to second @anthony1's request for self-service data dumps.
I'm in the process of importing / cleaning up data, and it's very inconvenient to have to request a dump through the neo4j team whenever I want a snapshot.
I've finally gotten around to play around with this CSV file.
I can access the file from my local. That's me showing it has 2 lines:
However, all the examples I'm seeing in the Importing CSV guide. Are having me parse the data manually and then specify the node/relationship structure (essentially schema) of my entire graph
LOAD CSV WITH HEADERS FROM 'file:///data.csv' AS row
MERGE (c:Company {companyId: row.Id, hqLocation: coalesce(row.Location, "Unknown")})
I was hoping since this was generated from neo4j, there would be an easy native way to import the data that it itself has generated. Please advise.
Unfortunately, relationship data isn't necessarily preserved in the CSV format, so regenerating a graph from it does take some work. However, in the time since this thread was started, we've created a new method of exporting your data as a backup dump. For now, that process requires a help ticket in our support portal. If you wouldn't mind opening a ticket there, and include the URI of the database you want to export, we can provide a secure link to you to download it and import it locally.
This same capability is the one we've spoken of earlier in this thread, that our developers are working on enabling within the console. So in the near future you'll be able to download these dumps directly, on your own.