Hi again,
Thanks Luanne for the follow up.
I've been experimenting a few but I am not confident I am heading in the right path, so i'd like to add some more context to our use case and share what i've been trying so far.
Context
We have a fairly average size data set, ~700k nodes and ~100M relations which we are looking forward to grow by two or three folds by end of year.
We query this data set in a real-time setting, we can tolerate no more than 5s response time.
- The count of
s nodes is 30 times more than that of t nodes.
- We cannot index hint
t nodes since these can only be filtered by the query params provided above.
- Our current setup is as follows:
- Driver: using official Golang driver
- Neo4j causal cluster of 3 core and 2 read replicas. The cluster is managed by Kubernetes, so Neo4j is hosted within Docker containers and not on the machine directly
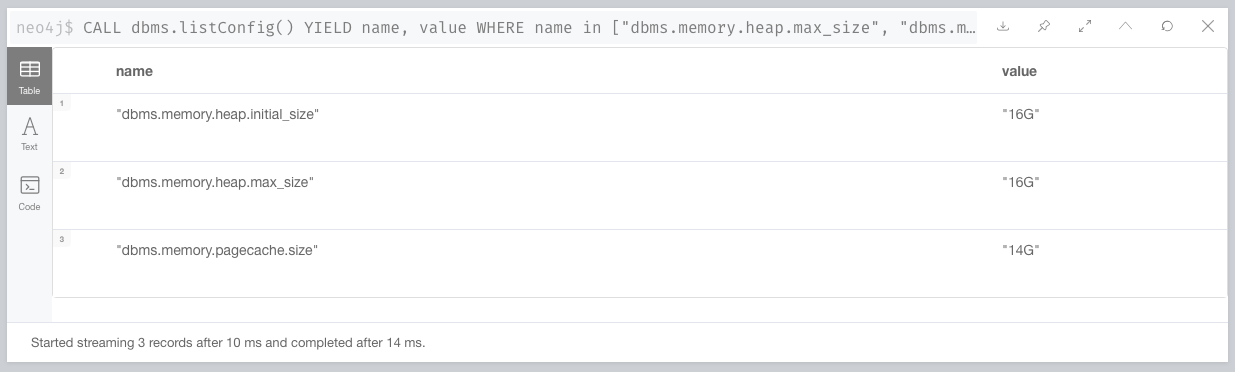
- Each core has a maximum of 3CPU units and 20Gi RAM with configuration of heap:
heap.max_size and heap.initial_size are 13Gi
- Read replicas are configured with a maximum of 3CPU units and 18Gi RAM (read replicas are irrelevant to this question)
- All our indexes are native.
Experimentation
Avoid relation property query
We removed the infamous r.affinity > 0 where clause in favour of an additional property filter t.is_identification_enabled = true on the t node itself, leveraging the following query:
MATCH (s:AudienceSegment {checksum: $checksum})<-[r:BELONGS_TO]-(t:Talent:Instagram)
WHERE t.iscore IS NOT NULL
AND t.iscore >= $iScoreFrom
AND t.iscore <= $iScoreTo
AND t.followers >= $followersFrom
AND t.followers <= $followersTo
AND t.avg_video_views >= $videoViewsFrom
AND t.avg_video_views <= $videoViewsTo
AND t.avg_engagement >= $avgEngagementFrom
AND t.avg_engagement <= $avgEngagementTo
AND t.is_identification_enabled = true
RETURN t AS talent, r AS belongsTo
ORDER BY t.iscore ASC
SKIP $offset LIMIT $limit;
With no difference whatsoever in query performance. Got to mention that we do allow to ORDER BY r.affinity.
Results: Cypher version: CYPHER 3.5, planner: COST, runtime: SLOTTED. 131321 total db hits in 8330 ms. Profile
Add JOIN hint
The only hint I think we can provide to the query planner is a Join hint, since we cannot hint any index on t nodes for the aforementioned reasons. Nonetheless I did try other hints mainly, SCAN hints. Leading to the following query:
MATCH (s:AudienceSegment {checksum: $checksum})<-[r:BELONGS_TO]-(t:Talent:Instagram)
USING JOIN ON t
WHERE t.iscore IS NOT NULL
AND t.iscore >= $iScoreFrom
AND t.iscore <= $iScoreTo
AND t.followers >= $followersFrom
AND t.followers <= $followersTo
AND t.avg_video_views >= $videoViewsFrom
AND t.avg_video_views <= $videoViewsTo
AND t.avg_engagement >= $avgEngagementFrom
AND t.avg_engagement <= $avgEngagementTo
AND t.is_identification_enabled = true
RETURN t AS talent, r AS belongsTo
ORDER BY t.iscore ASC
SKIP $offset LIMIT $limit;
One thing to note is that with the JOIN hint the number DB hits skyrocketed but seems that response time has been reduced, or at leased that is the impression we got from profiling.
Results: Cypher version: CYPHER 3.5, planner: COST, runtime: SLOTTED. 544294 total db hits in 5295 ms. Profile
Once deployed to our testing environment we could not note any improvement.
I find it very hard to explain how the latter query, using JOIN hint is more performant despite the huge number of DB hits, ~78% of our entire node population!
One thing that have been a hurdle to workaround is cached query results, we are not able to benchmark different approaches to query tuning due to that. We could not find a way to disable caching, not sure if this CYPHER replan=force is the way to go, but it is only supported in v4.x.
That said
- Do you think I should try something else that might have slipped unnoticed? What would that be?
- Please elaborate on the more performant yet less cost effective JOIN hint query, how is it possible and/or whether my understanding of profiling results are wrong?
- Please advise on how to disable caching results, for a better benchmarking experience.
Thanks!
Have a nice day.
k.