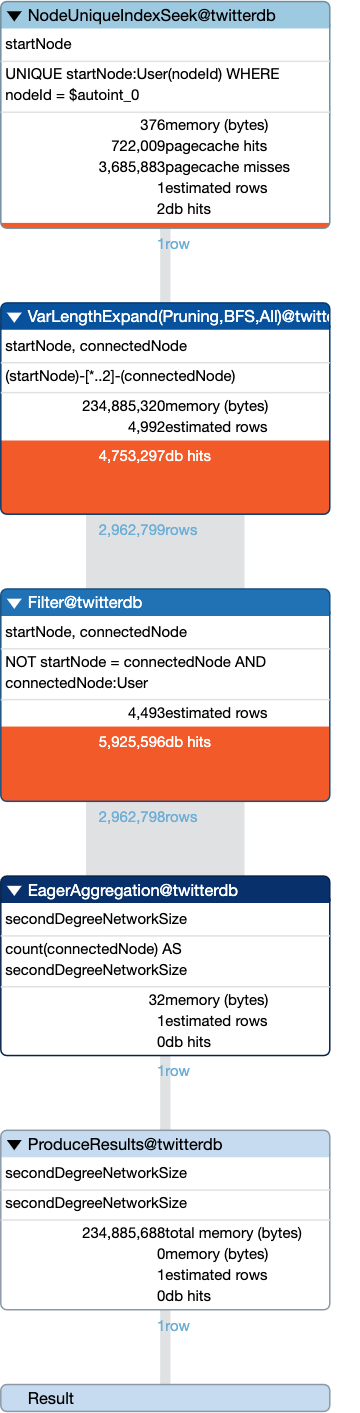
What is the most efficient way to fetch a 2nd degree network (friends and friends of friends) of a node in a social graph?
I tried this:
MATCH (startNode:User {nodeId: 1}) // Find the starting User node
MATCH (startNode)-[*1..2]-(connectedNode:User) // Find distinct User nodes within 1 to 2 hops
WHERE startNode <> connectedNode // Exclude the starting node itself
RETURN count(DISTINCT connectedNode) AS secondDegreeNetworkSize;
I decided to try it on a real social network dataset (40 million nodes, 1 billion edges) from one of the public collections, and it took 130 seconds to fetch and count the nodes in the 2nd degree network of 2.9 million nodes. On average, the users have couple hundred connections or less, but there are outliers, of course.
It took longer than I was willing to wait (I aborted) to compute the 3rd degree network—even though at first I thought it should be easy.
I am new to cypher and graph databases—a student trying to learn. Is this the best it can do, or can my query be optimized?
Is there a more suitable data solution for this task that can solve this problem in a smaller amount of time?
I think I read somewhere that graph databases can make tens or even hundreds of millions of traversals per second per core on a modern CPU, and I ran it on a powerful M3Max MacBook with way more RAM than the database size, but even a 2nd degree network of just 1 million nodes took 30 seconds to compute.
So, did I do it wrong? Seems a bit slow for my hardware.
a. is there an index in :User(nodeId)? if not then the 1st line is going to scan / examine every :User node to see if it has a nodeId and value 1?
b. the 2nd line. there is no relationship direction (i.e. -[*1..2]-(connectedNode:User) ) is that expected or should it be `-[*1..2]->(connectedNode:User) >?
Yes, I've indexed it. What's the best way for me to verify?
The schema output above does not mention it?
I wanted the 2nd and 3rd (not realistic, as I see now, so just 2nd, I guess) of those whom the starting node follows + those whom the node's friends follow. I.e., outgoing edges from S to outer frontier.
How would I do that properly and most efficiently?
No. I will study that. Thank you! Is that just for the Mac platform?
Thank you for the link. Yeah, Neo4j is probably the best graph DB on the market, and the most mature one.
So, I am essentially familiarizing myself with what and how far the graph algos/DBs in general can handle in real life applications. I just wanted to learn how I can optimize and squeeze every ounce of performance, and Dana was kind to share a bunch of pointers—I have things to read on now.