
Excuse the lack of vocabulary from a noob (I've only just started).
In a Graph Academy section the model is:
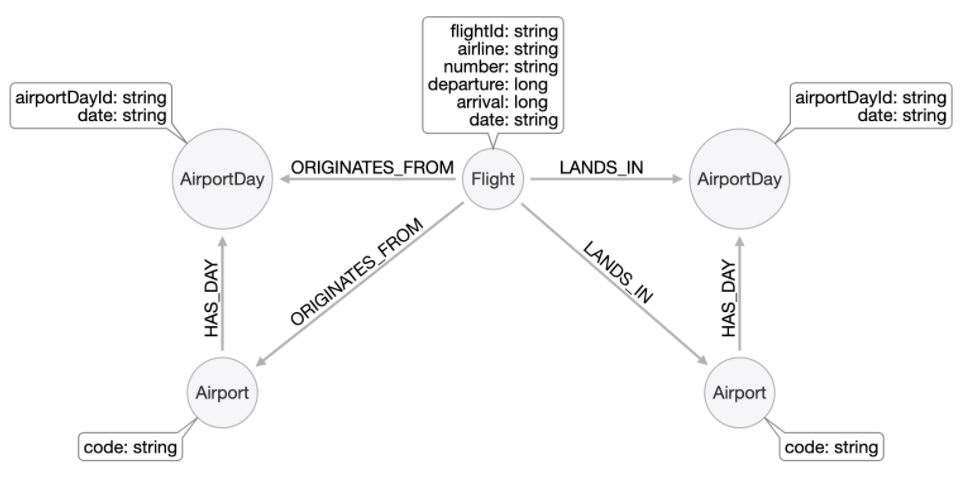
The question is "Find all the flights going from Los Angeles (LAS) to Chicago Midway International (MDW) on the 3rd January, 2019."
Query 1: The proposed query is:
PROFILE MATCH (origin:Airport {code: 'LAS'})-
[:HAS_DAY]->(:AirportDay {date: '2019-1-3'})<-
[:ORIGINATES_FROM]-(flight:Flight),
(flight)-[:LANDS_IN]->
(:AirportDay {date: '2019-1-3'})<-
[:HAS_DAY]-(destination:Airport {code: 'MDW'})
RETURN origin, destination, flight
Cypher version: CYPHER 4.2, planner: COST, runtime: PIPELINED. 6453 total db hits in 12 ms.
Query 2: I changed the query slightly and removed the comma:
PROFILE
MATCH (origin:Airport {code: 'LAS'})-
[:HAS_DAY]->(:AirportDay {date: '2019-1-3'})<-
[:ORIGINATES_FROM]-(flight:Flight)-[:LANDS_IN]->
(:AirportDay {date: '2019-1-3'})<- [:HAS_DAY]-
(destination:Airport {code: 'MDW'})
RETURN origin, destination, flight
Cypher version: CYPHER 4.2, planner: COST, runtime: PIPELINED. 4263 total db hits in 10 ms.
The result sets are the same, but there are fewer db hits.
What's the recommended one? Is it always the one that results in fewer db hits?