I ran into the following on a CORE-only cluster: "No write operations are allowed directly on this database. Writes must pass through the leader. The role of this server is: FOLLOWER".
I access the node via HTTP, not Bolt (Because we started the project in PHP, when there was no Bolt connecort yet
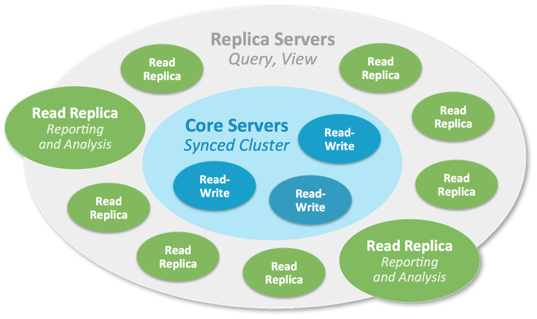
These terms are from the underlying raft consensus algorithm. A follower receives updates from the leader. A leader decides to commit a transaction based on the number of followers that confirmed that they have received an update.
A follower is also a candidate to become a leader when a leader election is triggered.
A read replica receives updates, but does not count towards consensus. It also will never become a leader. Read replicas are a bit like the database equivalent of a content-delivery network.
The reason you can't write to a follower is that there is no internal forwarding to the leader. The bolt drivers handle routing on the client-side by receiving routing information and relying on explicit read or write session types to decide where to send a given query.
Theoretically server-side routing would also forward http requests. I'm double checking on this as our documentation does not indicate whether or not it is possible. Will update this thread with whatever I learn.
Regarding clusters: the primary purpose of the cluster is resilience to failure. For reading, you can easily scale up read capacity by adding more members. However write operations are always serialized transactions. The data consistency guarantees would require multiple writers to coordinate their writes, returning to a serialized operation. Multiple writers are only possible with isolated data. A graph, by definition, is connected.
The way to crack that is to allow multiple graphs, which can then be independently updated. The problem is then what to do about querying across the independent graphs. That is the problem space of Neo4j Fabric.
{kind=link}