I am working with citation data. In academia, paper_0 will be cited by paper_1 which will be cited by paper_2, so on and so forth. During the creation of our database, we added labels to all paper_1 nodes called one_hop and labels to all paper_2 nodes called two_hop. It becomes complicated when a one_hop node is also a two_hop node to a different paper. This means on any given node, it could have a one_hop label and a two_hop label.
I need a solution to that overwrites the label of the nodes when running, what we call the two hop analysis, so each node has one label which can be used to color the nodes in Bloom appropriately. In addition, the intended solution will not update the graph itself. That is where I found Virtual Nodes and Relationships.
I am close to a solution but it is not working perfectly:
Match (n:Paper {paperid: '7608367'})
OPTIONAL MATCH (n)<-[r1:REFERS]-(o:one_hop)
OPTIONAL MATCH (o)<-[r2:REFERS]-(t:two_hop)
CALL apoc.create.vNode(['one_hop'],o{.*}) yield node as one
CALL apoc.create.vNode(['two_hop'],{title:t.papertitle}) yield node as two
call apoc.create.vRelationship(one,'REFERS',{},n) yield rel as rel1
call apoc.create.vRelationship(two,'REFERS',{},one) yield rel as rel2
return n, one, two, rel1, rel2
The above seems to be creating duplicated nodes. See screenshot below:
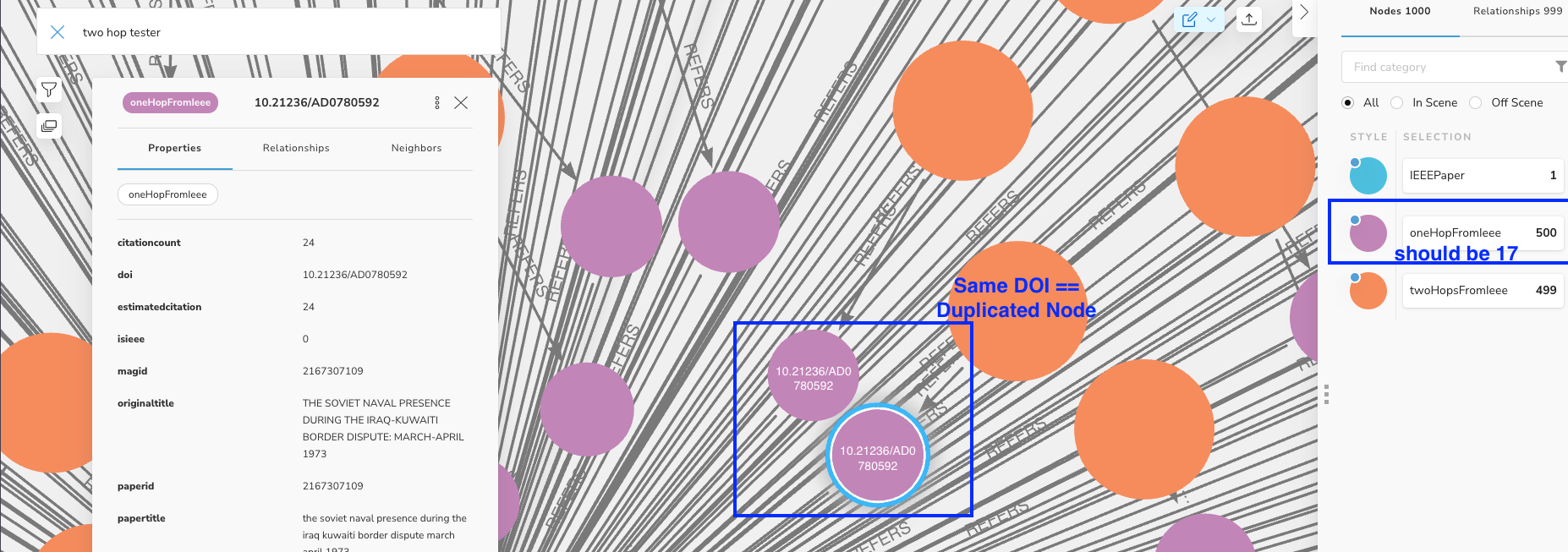
If I were solving this issue in SQL I would simply group by n, one but I am not sure how to do that in Cypher.
I am relatively new to Neo4j so I appreciate any patience afforded :)
Thanks in advance for any help and let me know if there are questions