





My neo4j database has been loaded via NeoSemantics. This means that every node has a “Resource” label and also has its own label depending on the type of object. For each node I’ve also added an internalId field that is unique across all nodes in the graph.
Here is my first query:
PROFILE
MATCH (n:Resource&Organization)-[:documentSource]->(art: Resource&Article)
WHERE n.internalId > 0
AND art.datePublished >= datetime('2025-07-01')
AND n.internalMergedSameAsHighToUri IS NULL
RETURN DISTINCT(n)
ORDER BY n.internalId
LIMIT 100
This performs ok: planner: COST, runtime: PIPELINED. 441936 total db hits in 8932 ms.

But when I try the equivalent query with another label, e.g:
PROFILE
MATCH (n:Resource&AboutUs)-[:documentSource]->(art: Resource&Article)
WHERE n.internalId > 0
AND art.datePublished >= datetime('2025-07-01')
AND n.internalMergedSameAsHighToUri IS NULL
RETURN DISTINCT(n)
ORDER BY n.internalId
LIMIT 100
The performance degrades dramatically: planner: COST, runtime: PIPELINED. 10152421 total db hits in 35352 ms.
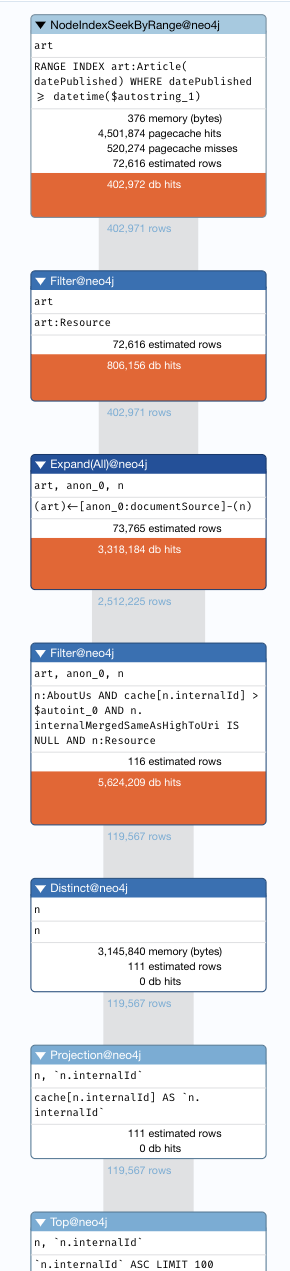
Interestingly, this uses a different index to start its query.
I then tried to hint to use the same index as the Resource&Organization query, like so:
PROFILE
MATCH (n:Resource&AboutUs)-[:documentSource]->(art: Resource&Article)
USING INDEX n:Resource(internalId)
WHERE n.internalId > 0
AND art.datePublished >= datetime('2025-07-01')
AND n.internalMergedSameAsHighToUri IS NULL
RETURN DISTINCT(n)
ORDER BY n.internalId
LIMIT 100
This helped a bit but it's still pretty dire by comparison: planner: COST, runtime: PIPELINED. 34836518 total db hits in 25676 ms.

Some context:
There are about 1.5m matching Organization nodes, of which each one could have many (>10) Articles attached. There are about 1 million matching AboutUs nodes, each of which is only likely to have 1 Article attached.
My question: What can I do to optimize these queries, or at least make them work to a similar level of quality?
