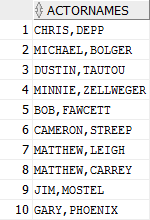
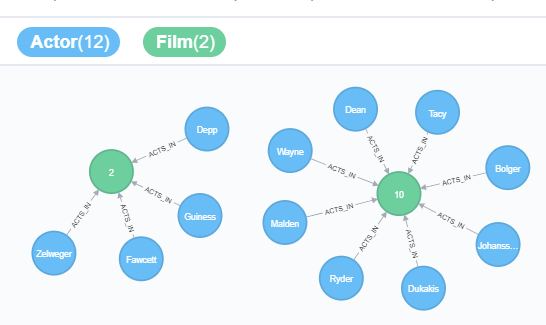
Dear all,
i have a problem writing a cypher query to get the correct result for a hierarchic result.
Here you can see the initial ERD from my SQL database:
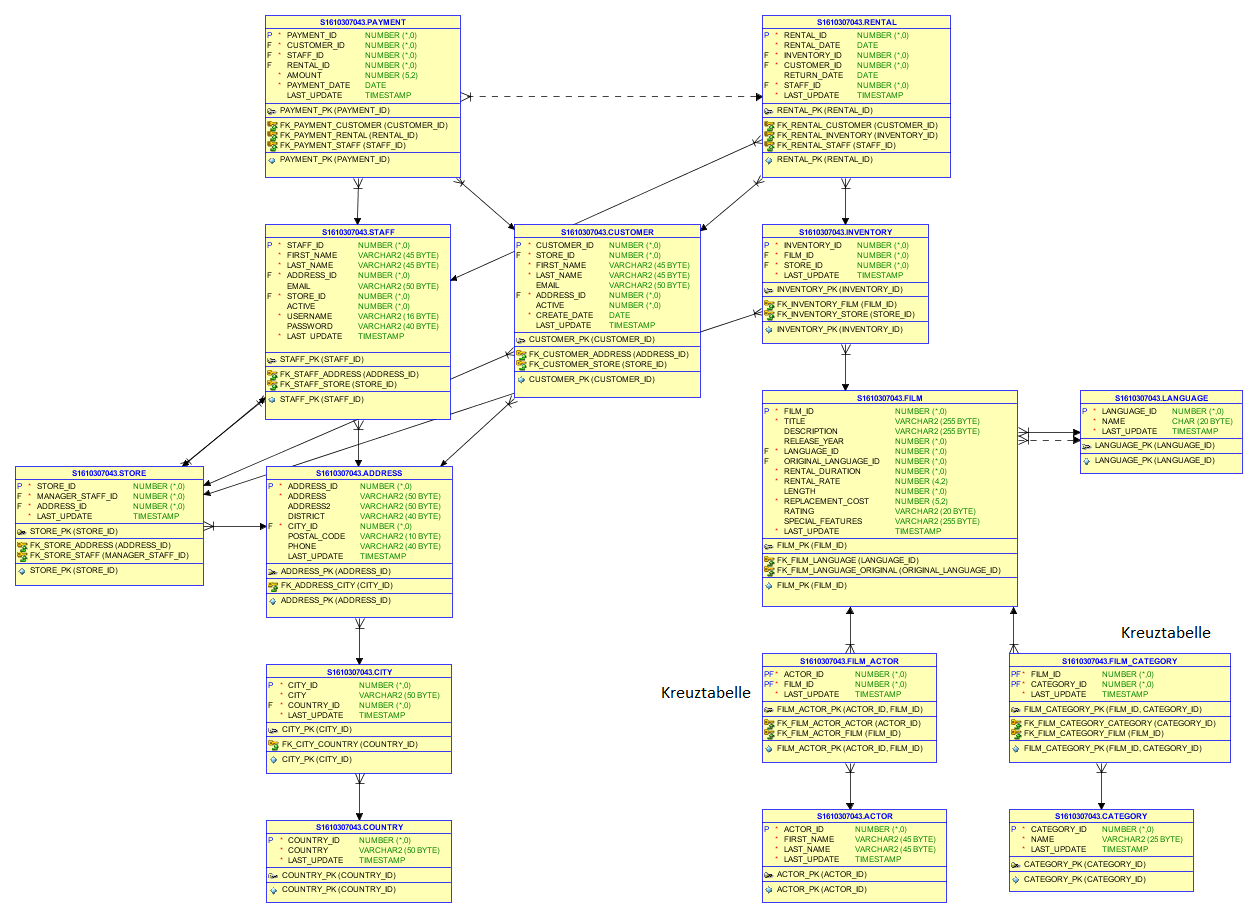
I already wrote all needed cypher statements to load data, set index and create relationships. (see at the end of the ticket).
No i want to solve the following problem:
"I want to create a social netowrk for actors. All actors which play together already know each other. The system should provide a list of new contact suggestions that provides actor information from actor that know another actor over exactly one other actor. For having a detailed result the result should be given for actor "NICK WAHLBERG" and should only contain the first 13 film(FILM_ID <14).
In SQL i wrote the following query:

Is someone able to help me creating a cypher query to get the same result?
Thank you very much in advance
Here you can find all statements to create the graph:
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/payment.csv" AS row
CREATE (n:PAYMENT)
SET n = row
, n.AMOUNT = toFloat(row.AMOUNT)
, n.PAYMENT_DATE = row.PAYMENT_DATE
, n.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/customer.csv" AS row
CREATE (n:CUSTOMER)
SET n = row
, n.FIRST_NAME = row.FIRST_NAME
, n.LAST_NAME = row.LAST_NAME
, n.EMAIL = row.EMAIL
, n.ACTIVE = row.ACTIVE
, n.CREATE_DATE = row.CREATE_DATE
, n.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/staff.csv" AS row
CREATE (n:STAFF)
SET n = row
, n.FIRST_NAME = row.FIRST_NAME
, n.LAST_NAME = row.LAST_NAME
, n.PICTURE = row.PICTURE
, n.EMAIL = row.EMAIL
, n.ACTIVE = row.ACTIVE
, n.USERNAME = row.USERNAME
, n.PASSWORD = row.PASSWORD
, n.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/address.csv" AS row
CREATE (n:ADDRESS)
SET n = row
, n.ADDRESS = row.ADDRESS
, n.ADDRESS2 = row.ADDRESS2
, n.DISTRICT = row.DISTRICT
, n.POSTAL_CODE = row.POSTAL_CODE
, n.PHONE = row.PHONE
, n.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/city.csv" AS row
CREATE (n:CITY)
SET n = row
, n.CITY = row.CITY
, n.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/country.csv" AS row
CREATE (n:COUNTRY)
SET n = row
, n.COUNTRY = row.COUNTRY
, n.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/store.csv" AS row
CREATE (n:STORE)
SET n = row
, n.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/rental.csv" AS row
CREATE (n:RENTAL)
SET n = row
, n.RENTAL_DATE = row.RENTAL_DATE
, n.RETURN_DATE = row.RETURN_DATE
, n.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/inventory.csv" AS row
CREATE (n:INVENTORY)
SET n = row
, n.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/film.csv" AS row
CREATE (n:FILM)
SET n = row
, n.TITLE = row.TITLE
, n.DESCRIPTION = row.DESCRIPTION
, n.RELEASE_YEAR = row.RELEASE_YEAR
, n.RENTAL_DURATION = row.RENTAL_DURATION
, n.RENTAL_RATE = row.RENTAL_RATE
, n.LENGTH = row.LENGTH
, n.REPLACEMENT_COST = row.REPLACEMENT_COST
, n.RATING = row.RATING
, n.SPECIAL_FEATURES = row.SPECIAL_FEATURES
, n.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/language.csv" AS row
CREATE (n:LANGUAGE)
SET n = row
, n.NAME = row.NAME
, n.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/actor.csv" AS row
CREATE (n:ACTOR)
SET n = row
, n.FIRST_NAME = row.FIRST_NAME
, n.LAST_NAME = row.LAST_NAME
, n.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/category.csv" AS row
CREATE (n:CATEGORY)
SET n = row
, n.NAME = row.NAME
, n.LAST_UPDATE = row.LAST_UPDATE;
CREATE INDEX ON :PAYMENT(PAYMENT_ID);
CREATE INDEX ON :CUSTOMER(CUSTOMER_ID);
CREATE INDEX ON :STAFF(STAFF_ID);
CREATE INDEX ON :ADDRESS(ADDRESS_ID);
CREATE INDEX ON :CITY(CITY_ID);
CREATE INDEX ON :COUNTRY(COUNTRY_ID);
CREATE INDEX ON :STORE(STORE_ID);
CREATE INDEX ON :RENTAL(RENTAL_ID);
CREATE INDEX ON :INVENTORY(INVENTORY_ID);
CREATE INDEX ON :FILM(FILM_ID);
CREATE INDEX ON :LANGUAGE(LANGUAGE_ID);
CREATE INDEX ON :ACTOR(ACTOR_ID);
CREATE INDEX ON :CATEGORY(CATEGORY_ID);
MATCH (p:PAYMENT), (c:CUSTOMER)
WHERE p.CUSTOMER_ID = c.CUSTOMER_ID
CREATE (p)-[:PAYED_FROM]->(c);
MATCH (p:PAYMENT), (s:STAFF)
WHERE p.STAFF_ID = s.STAFF_ID
CREATE (p)-[:RECEIVED_BY]->(s);
MATCH (p:PAYMENT), (r:RENTAL)
WHERE p.RENTAL_ID = r.RENTAL_ID
CREATE (p)-[:PAYED_FOR]->(r);
MATCH (c:CUSTOMER), (s:STORE)
WHERE c.STORE_ID = s.STORE_ID
CREATE (c)-[:WORKS_AT]->(s);
MATCH (c:CUSTOMER), (a:ADDRESS)
WHERE c.ADDRESS_ID = a.ADDRESS_ID
CREATE (c)-[:LIVES_AT]->(a);
MATCH (s:STAFF), (s:STORE)
WHERE s.STORE_ID = s.STORE_ID
CREATE (s)-[:STA_WORKS_AT]->(s);
MATCH (s:STAFF), (a:ADDRESS)
WHERE s.ADDRESS_ID = a.ADDRESS_ID
CREATE (s)-[:STA_LIVES_AT]->(a);
MATCH (c:CITY), (a:ADDRESS)
WHERE c.CITY_ID = a.CITY_ID
CREATE (a)-[:LOCATED_IN]->(c);
MATCH (c:CITY), (co:COUNTRY)
WHERE c.COUNTRY_ID = co.COUNTRY_ID
CREATE (c)-[:PART_OF]->(co);
MATCH (s:STORE), (st:STAFF)
WHERE s.MANAGER_STAFF_ID = st.STAFF_ID
CREATE (s)-[:MANAGED_BY]->(st);
MATCH (S:STORE), (a:ADDRESS)
WHERE S.ADDRESS_ID = a.ADDRESS_ID
CREATE (S)-[:LOCATED_AT]->(a);
MATCH (r:RENTAL), (i:INVENTORY)
WHERE r.INVENTORY_ID = i.INVENTORY_ID
CREATE (r)-[:INVENTORIED]->(i);
MATCH (r:RENTAL), (c:CUSTOMER)
WHERE r.CUSTOMER_ID = c.CUSTOMER_ID
CREATE (r)-[:RENTED_FROM]->(c);
MATCH (r:RENTAL), (s:STAFF)
WHERE r.STAFF_ID = s.STAFF_ID
CREATE (r)-[:RENTED_BY]->(s);
MATCH (i:INVENTORY), (f:FILM)
WHERE i.FILM_ID = f.FILM_ID
CREATE (i)-[:CONTAINS]->(f);
MATCH (i:INVENTORY), (s:STORE)
WHERE i.STORE_ID = s.STORE_ID
CREATE (i)-[:INVENTORIED_AT]->(s);
MATCH (f:FILM), (l:LANGUAGE)
WHERE f.LANGUAGE_ID = l.LANGUAGE_ID
CREATE (f)-[:HAS_LANGUAGE]->(l);
MATCH (f:FILM), (l:LANGUAGE)
WHERE f.ORIGINAL_LANGUAGE_ID = l.LANGUAGE_ID
CREATE (f)-[:HAS_ORIG_LANGUAGE]->(l);
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/film_actor.csv" AS row
MATCH (a:ACTOR), (f:FILM)
WHERE a.ACTOR_ID = row.ACTOR_ID AND f.FILM_ID = row.FILM_ID
CREATE (a)-[details:ACTS_IN]->(f)
SET details = row
, details.LAST_UPDATE = row.LAST_UPDATE;
LOAD CSV WITH HEADERS FROM "http://www.fimojules.at/data/film_category.csv" AS row
MATCH (c:CATEGORY), (f:FILM)
WHERE c.CATEGORY_ID = row.CATEGORY_ID AND f.FILM_ID = row.FILM_ID
CREATE (f)-[details:HAS_CATEGORY]->(c)
SET details = row
, details.LAST_UPDATE = row.LAST_UPDATE;