Hi there,
My original use-case is fetching all mutual relationships between two groups of nodes.
One of the groups of nodes contains a supernode (i.e. a node with a very high degree).
Let's call n the group of nodes that contains only regular nodes and sn the group of nodes that contains a supernode.
My cypher query is the following:
MATCH (sn)-[r]-(n)
WHERE ID(sn) in [1, 999] // node 999 has high degree (1163)
AND ID(n) in [2, 3] // nodes 1, 2 and 3 have a low degree (3)
RETURN r
I'm currently using Neo4j 3.3.0 to benchmark this query, and I noticed something very odd: the performance of the query depends on the names of the variables I am using for sn, n and r.
More particularly, the performances depend of the alphabetical order of the variables.
I have tried changing other things in the query:
- order of the
ID(x) in []statements - switching
(sn)-[r]-(n)for(sn)-[r]-(n)
But after lots of testing, the only change that has a consistent impact on the performance of the query is the alphabetical order of the variable names used for sn, n and r.
To test my query, I have the following process:
- I rename
sn,nandrto a different name (sn => v1,n => v2,r => v3) and profile my query. - then, I change the alphabetical order (e.g.
sn => v2,n => v3,r => v1) and profile again - etc.
Here are the results for all possible permutations:
-
sn => v1,r => v2,n => v3: FAST -
sn => v1,n => v2,r => v3: FAST -
r => v1,sn => v2,n => v3: SLOW (i.e. at least of DB hit for each relationship of supernode999) -
r => v1,n => v2,sn => v3: FAST -
n => v1,r => v2,sn => v3: SLOW (i.e. at least of DB hit for each relationship of supernode999) -
n => v1,sn => v2,r => v3: SLOW (i.e. at least of DB hit for each relationship of supernode999)
Profiling for each query:
-
profile match (v1)-[v2]-(v3) where id(v1) in [1, 999] and id(v3) in [2, 3] return v2
-
profile match (v1)-[v3]-(v2) where id(v1) in [1, 999] and id(v2) in [2, 3] return v3
upload limit -
profile match (v2)-[v1]-(v3) where id(v2) in [1, 999] and id(v3) in [2, 3] return v1
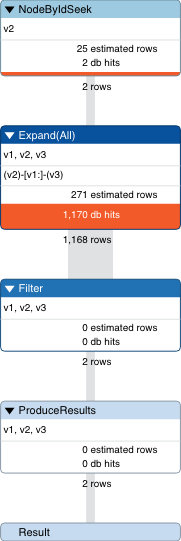
-
profile match (v3)-[v1]-(v2) where id(v3) in [1, 99] and id(v2) in [2, 3] return v1
upload limit -
profile match (v3)-[v2]-(v1) where id(v3) in [1, 999] and id(v1) in [2, 3] return v2
upload limit -
profile match (v2)-[v3]-(v1) where id(v2) in [1, 999] and id(v1) in [2, 3] return v3
upload limit

Having to worry about the alphabetical ordering of variable names in a query makes it quite difficult to try and make queries fast 
On the other hand, I might be on the wrong track, and I'm open to suggestions for alternative queries to get the same result in a more fast and stable way.
Best,
David