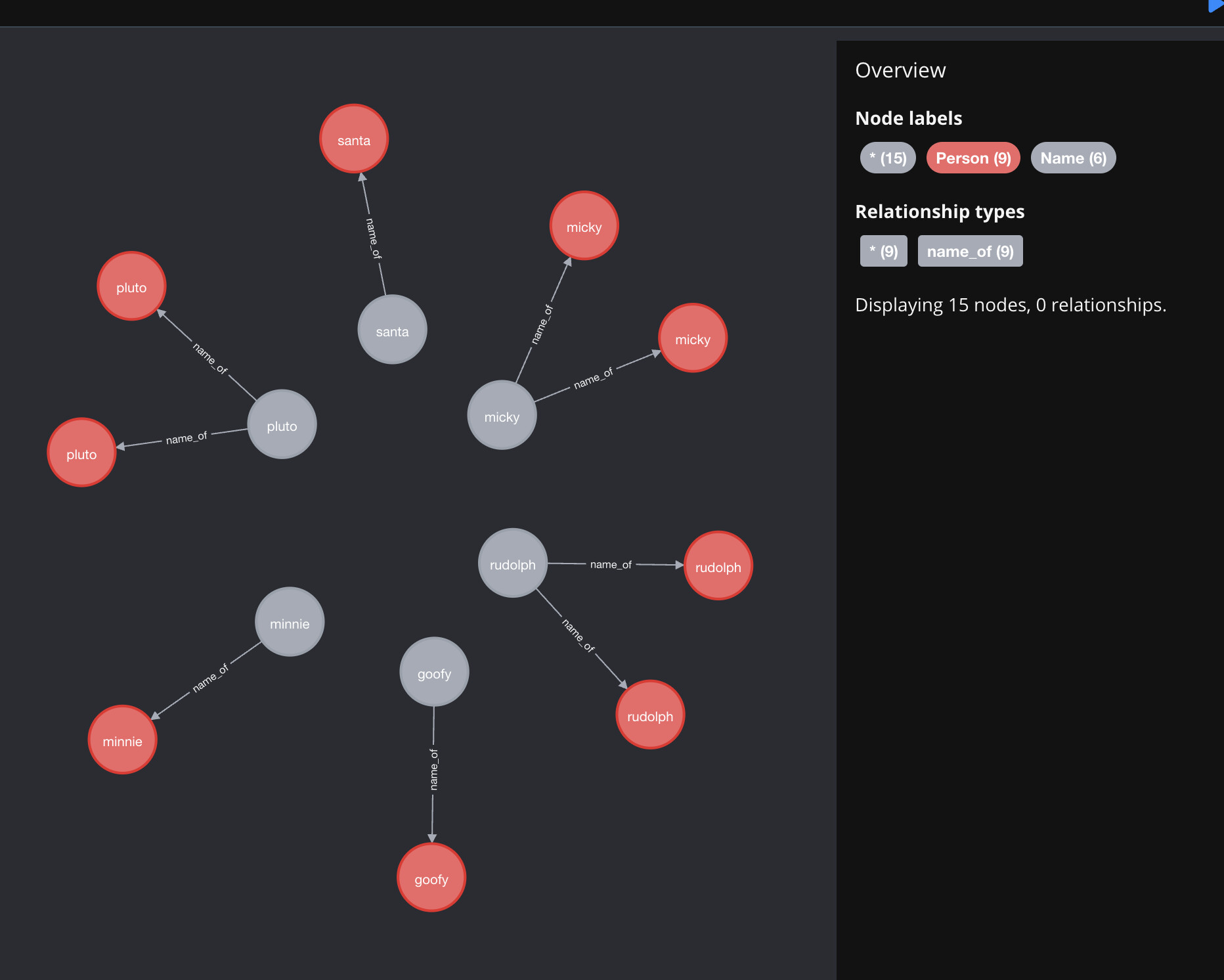
Neo4j beginner here. This seems like it should be a simple task, but I really cannot figure it out. I want to create a new set of nodes based off an existing set, merging them based on a unique value for a certain variable.
I have 3.7 million nodes of type "person" successfully loaded into my database. They have several variables attached. I want to create a new set of nodes called "name," where there is one node per unique value of the variable "person_name_cluster_key" in the "person" nodes. (Based on working with the data in R, I know that this should result in 2.3 million "name" nodes). I also want to bring over another variable called "person_name" for each of the new "name" nodes. Of the multiple "person" nodes merged, I don't care which "person" node this value is take from. Then, I want to relate each new "name" node to the original "person" nodes with a (n:name)-[:name_of]->(p:person) relationship.
I need the process to be iterative and computationally efficient since the dataset is so large. I feel like this should be really simple, but I'm stumped.
Note: 1 you need the ":auto" when executing the query in the browser or cypher-shell, but not otherwise.
Note 2: You definitely need an indexes on the labels and properties you are matching and merging on. This is not an issue with this query, as you are not matching on a specify property.
Note 3: I have not used the CONCURRENT TRANSACTIONS clause. It is relatively new.
Note 4: This may require a lot of memory due to the size of your database and the use of a COLLECT on your entire data set.