

Hello,
According to @glilienfield in this post UNWIND with inline variable, what am i doing wrong? i went using apoc.create.iterate to import approx 100MB of xmlFiles. It will generate 205000 nodes (8 different node labels) and 335542 relations (4 different types of relations). It tooks 1 hour and half with 202 failing queries for DEADLOCK (with NODE_RELATIONSHIP_GROUP_DELETE related error). Here is the message :
ForsetiClient[transactionId=15518, clientId=6471] can't acquire ExclusiveLock{owner=ForsetiClient[transactionId=15519, clientId=6507]} on NODE_RELATIONSHIP_GROUP_DELETE(36341) because holders of that lock are waiting for ForsetiClient[transactionId=15518, clientId=6471].\n Wait list:ExclusiveLock[\nClient[15519] waits for [ForsetiClient[transactionId=15516, clientId=6513],ForsetiClient[transactionId=15517, clientId=6503],ForsetiClient[transactionId=15518, clientId=6471]]]
First, i don't understand why i have errors related to DELETE operations. I didn't delete any node or relationship in my code. So i will explain my matter to see if someone has ideas to mitigate DEADLOCKS and improve performance.
On the fly, my application :
- generates queries,
- analyze them,
- factorized them with parameters.
The final parameterized queries look like :
CALL apoc.periodic.iterate(
"WITH $data AS data UNWIND data as row RETURN row",
"MERGE (nodea1:HypoComplexe:DOPLER:Maquette:ImportXML{id:row.params1_id})
ON CREATE SET nodea1 += row.properties2
MERGE (nodeb1:Hypothese:DOPLER:Maquette:ImportXML{id:row.params3_id})
ON CREATE SET nodeb1 += row.properties4
MERGE (nodea1)-[nodea1relnodeb1:CONTAINS]->(nodeb1)",
{batchSize:100, parallel:true,params:{data: $data}}
)
YIELD batch, operations;
I am calling them with this piece of Javascript code (it is dirty, i put everything to debug without nicely building my code) :
queriesToRun.forEach(async (objectToRun,idQuery) =>{
const session = this.driver.session();
queryAnalysis = objectToRun;
let queryExecTime = Date.now();
let resultQuery = null;
if(enablePerfLof)this.perfsAnalyser[queryAnalysis.id].push({step:'Deb Query', time:queryExecTime});
try {
const tx = session.beginTransaction();
resultQuery = await tx.run(objectToRun.query,objectToRun.varRun);
await tx.commit();
const records = resultQuery.records
for (let i = 0; i < records.length; i++) {
console.dir(records[i],{depth:null})
}
} catch (e) {
console.log('Req ERROR '+queryAnalysis.id+' : '+e+'\n\n');
queryExecTime = Date.now();
if(enablePerfLof)this.perfsAnalyser[queryAnalysis.id].push({step:'Error Query', time:(queryExecTime-(this.perfsAnalyser[queryAnalysis.id][0].time))});
}finally{
if(enablePerfLof)this.perfsAnalyser[queryAnalysis.id].push({step:'Close Query', time:(debExecTime-(this.perfsAnalyser[queryAnalysis.id][0].time))});
console.dir(resultQuery.records,{depth:null})
let debExecTime = new Date();
console.log(debExecTime.toISOString());
await session.close()
debExecTime = Date.now();
if(enablePerfLof)this.perfsAnalyser[queryAnalysis.id].push({step:'End Query',time:(debExecTime-(this.perfsAnalyser[queryAnalysis.id][0].time))});
}
});
According to my debug output, the total import could be factorized in six types of queries, here is a table with number of query call for each parameterized query :
Query 1
Query 2
Query 3
Query 4
Query 5
Query 6
number of call
382
201
162252
514
2725
21
Fail(nCall)
NO
NO
YES(202)
NO
NO
NO
Here is the Query 6 with deadlocks :
CALL apoc.periodic.iterate(
"WITH $data AS data UNWIND data as row RETURN row",
"MERGE (nodea1:HypoComplexe:DOPLER:Maquette:ImportXML{id:row.params1_id})
ON CREATE SET nodea1 += row.properties2
MERGE (nodeb1:Hypothese:DOPLER:Maquette:ImportXML{id:row.params3_id})
ON CREATE SET nodeb1 += row.properties4
MERGE (nodea1)-[nodea1relnodeb1:CONTAINS]->(nodeb1)
MERGE (nodea2:Ouvrage:DOPLER:Maquette:ImportXML{name:row.params5_name})
MERGE (nodea2)<-[nodea2relnodeb1:CONCERNS]-(nodeb1)",
{batchSize:100, parallel:true,params:{data: $data}}
)
YIELD batch, operations;
Here is the situation with deadlocks Graph Image here :
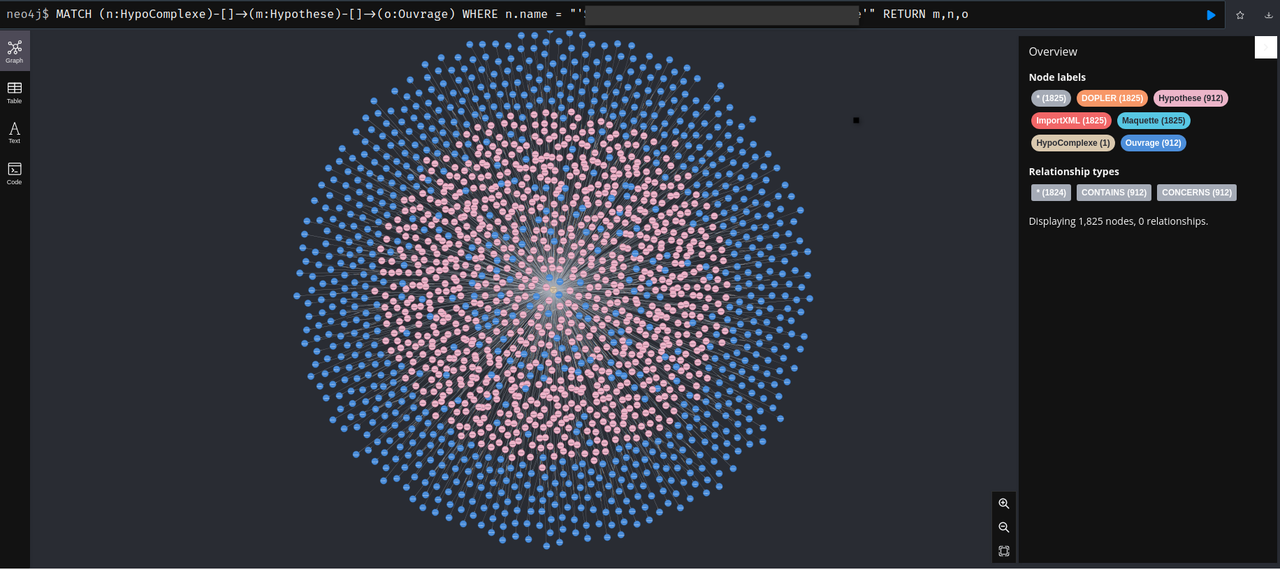{kind=link}
- node in the center (brown) is nodea1 in the query (Label HypoComplexe)
- rose node is nodeb1 in the query (Label Hypothese)
- blue node is nodea2 in the query (Label Ouvrage)
When the query executes, nodea1 may exists (He is created by Query 1 or Query 4 or is already in the database, created in a previous import). nodea2 and nodeb1 may exists with previous executions in the same import or in a previous import. So everything is in MERGE.
An instance of this query is called for each pattern of (Hypothese)-[:CONCERNS]->(Ouvrage), MERGE on nodea1(HypoComplexe) is to ensure with have a reference to bind nodeb1(Hypothese) with a relation with CONTAINS type.
There is 912 (Hypothese)-[:CONCERNS]->(Ouvrage) patterns in this case. Each couple require lock on brown node (HypoComplexe). I think this is were deadlocks occurs
How can i mitigate this?
I know setting parallel to false will do the trick. But it already takes 1h30 to import 260 000 nodes in parallel.
How to balance performances and deadlocks? I try to focus on Query 6 which represents most of my queries.
Is there any mechanism to manually place a lock on a node during a query to avoid such problems?
Is there any other strategy or workaround?
Maybe with trying merging a first time the Node nodea1(HypoComplexe) and after only MATCH clauses but it will be a nightmare to develop.
I am open to exchange on your ideas
Thank you