Hi, All I am new to the graph world. I am trying to dynamically generate the graph given spacy to do the tokenization and attach POS of each word as a property to each node? What is the best way to approach this kind of problem?
Suppose I have 2 sentences that I have created using the below code
WITH split(tolower("His dog eats turkey on Tuesday")," ") as text
Unwind range(0,size(text)-2) AS i
MERGE (w1:Word {name: text[i]})
MERGE (w2:Word {name: text[i+1]})
MERGE (w1)-[:NEXT]->(w2)
RETURN w1, w2
WITH split(tolower("My cat eats fish on Saturdays")," ") as text
Unwind range(0,size(text)-2) as i
MERGE (w1:Word {name: text[i]})
MERGE (w2:Word {name: text[i+1]})
MERGE (w1)-[:NEXT]->(w2)
RETURN w1, w2
My workflow with Spacy and Neo4J is to pass text from a node (such as an abstract on a document node). I run Spacy to get features of interest such as noun chunks or words. I then create word nodes and attach relationships to the originating document. Now the challenge for your use case is that POS for a given word can have very different values. For example and issue have when I have multiple documents with the same word nodes.
"A process to etch a wafer.."
"A process chamber to etch a wafer.."
"Process the wafer according.."
The POS of "process" is noun, adjective, and verb so attaching it to the node process is problematic. That leaves the relationship but you will need a convention since you are connecting two nodes with one relationship and where to put the value.
Perhaps you can elaborate on what you need to do with the value and you workflow.
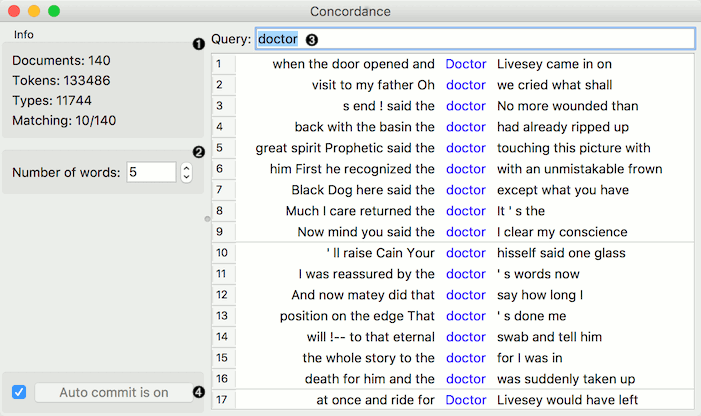
Concordance finds the queried word in a text and displays the context in which this word is used.
The idea is to implement it through graph for obvious reasons because graph traversal would be very easy and effective. It makes sense to use a graph-based approach here.
So I can query about a word and see in what context that word has been used. Since I am still very new to graph that is why I am not sure what is the best practice to perform this exercise. But my question still remains the same "
Any help or a pseudo code will be highly appreciated. Thanks a million
You can put the POS tag into the relationship that connects the words. For example if you are looking at "doctor" as word node and then the word next might use the relationship "next", you could put the POS into that relationship. The choice now becomes since the relationship is touching two words you might want to have two properties in "next" such as "POS_from" and "POS_to". so in Spacy you would capture the POS tags of the words and create the relationship within Python client and set the properties. tied to that relationship.
Andy
Thanks @andy_hegedus for your response could you please share the pseudo code if possible. I am still not able to get my head around it as I am new to Neo4j. In Python NLP what I have done is below now how to get this in neo4j graph.
Your original structure had word nodes connected by a relationship, "next".
Since the "next" relationship has a direction I would suggest that use attach the POS values into the specific relationships. To that end within python I would create a data table that has (setting all the words to lowercase.
Word1, Word2, Pos1,Pos2
In your example:
his, dog, PRON, NOUN
dog, eats,NOUN,VERB
eats, turkey,VERB,PROPN
turkey, on, PROPN, ADP
on, tuesday, ADP,PROPN
I would then create the word nodes with the unique property being term.
Assuming you are going to bring it through a csv file. (I find it faster in python to create sci and then pass the cyphers commands as opposed to going line by line in python)
Merge (w1:word{term:row.Word1)
Merge(W2:word{term:row.Word2)
Merge (W1)-[r:Next]->(W2)
set r.start = row.POS1
set r.end = row.POS2
Then the words are connected and you have the POS in the relation properties.
Andy
Hi Andy, Thanks for providing clarity. However, I tried doing the exercise using pandas dataframe. Doesn't seem to work for me. Getting error 'ValueError: dictionary update sequence element #0 has length 3; 2 is required. May be I am not passing the parameters correctly