In this post we’re going to analyse the Twitter social graph of the Neo4j community using graph algorithms.

Many graph algorithms originated from the field of social network analysis, and while I’ve wanted to build a twitter followers graph for a long time, the rate limits on its API have always put me off.
This changed a couple of weeks ago when Michael showed me the twint library.
Twint is an advanced Twitter scraping tool written in Python that allows for scraping Tweets from Twitter profiles without using Twitter’s API.
This library allows us to work around these rate limits and easily download twitter users and their followers, as well as the users that they follow.
The Twitter Social Graph
We’ll download all tweets for the search term neo4j OR "graph database" OR "graph databases" OR graphdb OR graphconnect OR @neoquestions OR @Neo4jDE OR @Neo4jFr OR neotechnology using the twint library, extract the users who wrote those tweets, and download the follower and following network for each of those users.

Once we’ve done that we’ll import all the users, their followers, and people that they follow into Neo4j.
If you want to follow along at home, you can execute the import script available on this gist. If we execute that script, we’ll have a graph like this:
Neo4j Twitter Graph
So that’s the data that we’ll be working with. Now let’s learn about the types of analysis that we’re going to do on this data.
Analysing the Neo4j social network
We’re going to do two types of analysis on the data.
Influencers
Let’s start with a definition:
A Social Media Influencer is a user on social media who has established credibility in a specific industry. A social media influencer has access to a large audience and can persuade others by virtue of their authenticity and reach.
We’ll use centrality algorithms like degree centrality, betweenness centrality, and PageRank to find the most important people in our graph
Sub Communities
We’ll use the Louvain community detection algorithm to find sub communities within the larger graph community.
These communities are likely to be language or interest based, and will help us learn about the different types of people who are interested in graphs.
NEuler: The Graph Algorithms Playground
We’re going to do this analysis using the Graph Algorithms Playground Graph App and the Neo4j Graph Algorithms Library.
You can read more about the app, including installation instructions, in the release blog post.
Now it’s time to explore the data and find the most important people and sub communities in the graph community.
Degree Centrality: Direct Importance
The simplest measure of influence is Degree Centrality, which measures the number of relationships connected to a node.
We can use this algorithm to find out which users have the most followers, which is the metric that people most frequently reference when identifying social media influencers:
Most important users based on Degree Centrality
The top three accounts are all organisations — unsurprisingly the Neo4j account has the most popular, and a lot of the graph community also follow TechCrunch and AWS Cloud.
After that we come across some people, including Emil (CEO of Neo4j), Kirk Borne (a big name in the Data Science community), and Michael Hunger (Director of Neo4j Labs).
These accounts are considered important because lots of other accounts opt in to seeing the content they publish on their timelines. If we want to broadcast some general information about graphs, these would be good accounts from which to do that.
PageRank: Transitive Importance
The PageRank algorithm measures the transitive influence or connectivity of nodes. This is the most famous graph algorithm, and was named after Google co-founder Larry Page.
We can use this algorithm to find important accounts based not only on whether they’re followed by lots of other accounts, but whether those accounts are themselves important.
Most important users based on PageRank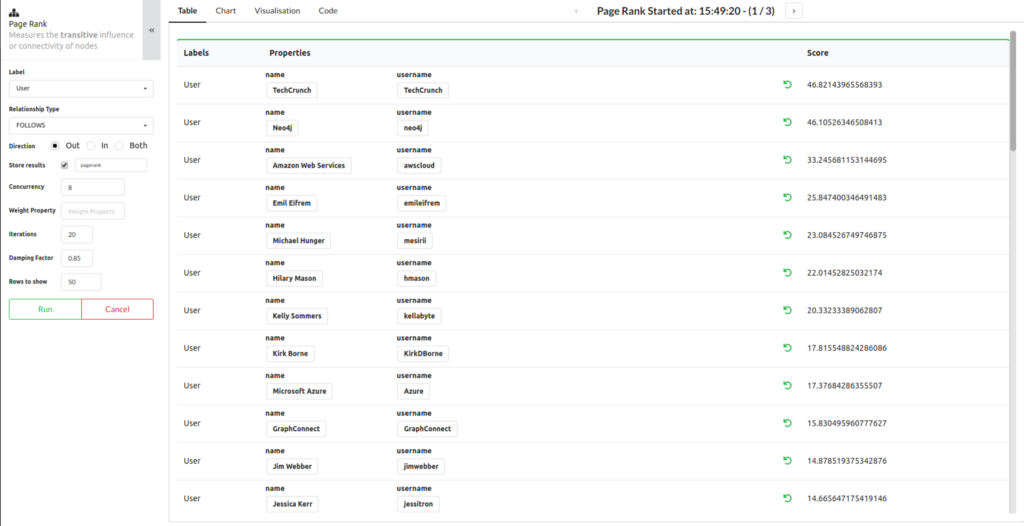
We see similar accounts as we did with the Degree Centrality algorithm. Jessica Kerr and Kelly Sommers are the only two accounts in the top 10 that didn’t appear in the Degree Centrality top 10.
If we wanted to post some content and have it spread across a large number of accounts, the accounts that rank highest for PageRank would be the best placed to post that content.
Betweenness Centrality: Local Bridges
The Betweenness Centrality algorithm detects the amount of influence a node has over the flow of information in a graph. It is often used to find nodes that serve as a bridge from one part of a graph to another.
We can use this algorithm to find people who are well connected to a sub community within the larger graph community:
Most important users based on Betweenness Centrality
Several of the accounts that had high Degree Centrality and PageRank feature here as well, but there are also some accounts we haven’t seen yet. Will Lyon and GraphQL Weekly are interesting additions — these two accounts are local bridges to the GRANDstack/GraphQL sub community.

Lucasoft.co.uk is another interesting one — after some exploration I believe this account is a local bridge into the PHP sub community.
If we wanted to find out what’s happening in these sub communities or if there’s some information that would be useful to those sub communities, one of our local bridges would be best placed.
We can explore those sub communities using community detection algorithms, so let’s do that next.
Communities: Louvain Modularity
The Louvain Modularity algorithm detects communities in networks, based on maximising a modularity score.
We can use this algorithm to find sub communities in the larger graph community:
Sub communities based on Louvain Modularity
We’ll run the algorithm in NEuler, but the results view isn’t very easy to consume, so we’ll write the following Cypher query to explore the resulting communities:
// Find all users and order them by community and PageRank scores
MATCH (u:User)
WITH u
ORDER BY u.louvain, u.pagerank DESC
// Return top 10 ranked nodes grouped by communitySub communities in the graph community
WITH u.louvain AS community, collect(u.name) AS people
RETURN community, people[..10]
ORDER BY size(people) DESC

From visualising inspecting the results, we can identify the following communities:
- 1 and 11 - Data Science
- 5 - Neo4j
- 2 - Spring
- 6 - Semantic Web
- 13 - Microsoft
- 3 - FileMaker
I find it fascinating that we can find this sub communities just by looking at the follower graph - the content of tweets posted by these accounts isn’t required.
Summary
In this post we’ve learnt how to use the centrality and community detection algorithms in the Neo4j Graph Algorithms Library to explore a Twitter Graph.
If you enjoyed learning how to apply graph algorithms to make sense of data, you might like the O’Reilly Graph Algorithms Book that Amy Hodler and I wrote.
You can download a free copy from neo4j.com/graph-algorithms-book

Finding influencers and communities in the Graph Community was originally published in neo4j on Medium, where people are continuing the conversation by highlighting and responding to this story.