





So, my graph is modeled for retail transactions and it's fairly large - 250M nodes. Nodes in my graph are bidirectionally connected and are as follows:
- Customer (Has an outgoing edge to Transaction, Has an incoming edge from Transaction) (Red color)
- Card (Has an outgoing edge to Transaction, Has an incoming edge from Transaction) (Pink)
- Transaction (Has an outgoing edge to Card, Customer, Has incoming edge from Card, Customer) (Blue with transaction amount) (150M nodes)
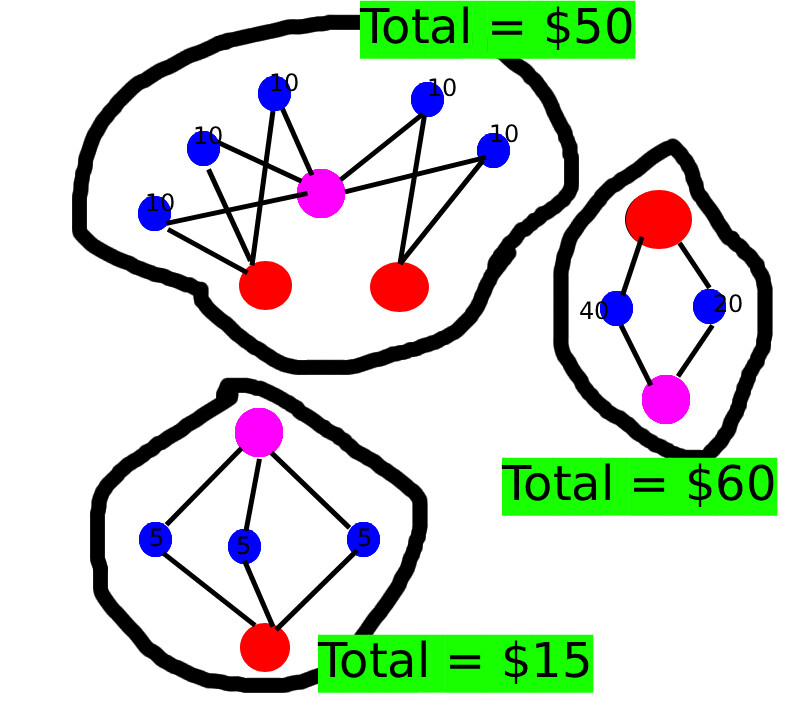
I am interested in knowing the components for which the total transaction amount is largest -- basically top n components by transaction amount. E.g. in the above figure component with $60 > $50 > $15. For this I'm using Graph Data Science library in conjunction with APOC.
However, since the data size is quite large in my case, the "graph projection" itself is taking too much time. It's taking around 7-8 hours to project all 150M nodes. Overall heap memory for the projection is ~10GB. Running gds.wcc.stream which then takes 10-15 mins to find the largest component. I want to know how I can further optimize my projection query to speed up my projections. Here's the query which I'm using to project my graph:
// Note I'm running this query over and over again from my java app until the graph is fully projected fully.
// In one query execution, some 500k nodes are projected from a "seed" of 50k nodes.
// I didn't used LIMIT before but it was way too slow, also with LIMIT I can mark the already visited nodes and don't visit them again for projection.
// Since transaction amount is in Transaction node, I'm only projection this node
MATCH (n:Transaction)
WHERE NOT n:AlreadySeen // Don't consider nodes which have been projected before
WITH n
LIMIT 50000
SET n:AlreadySeen // Mark the node as seen
WITH n
// I want to find all the transactions in a components -- basically all the Transaction nodes which I can reach starting from a given seed Transaction node
// I tried cypher before
// (n)-[*]->(m:Transaction)
// but apoc is somewhat faster
CALL apoc.path.subgraphNodes(n, {
minLevel: 1,
maxLevel: 299, // I've some pretty big components/clusters,
relationshipFilter: ">" // forward direction works given the nature of o
}) YIELD node
// Again, checking if it was not already seen before and filtering only transaction nodes
// Also, I am only target online transactions
// I have indexed transaction_mode field
WHERE (NOT node:AlreadySeen AND node:Transaction AND node.transaction_mode="ONLINE"
// marking the reachable transaction nodes as AlreadySeen so we don't consider them in further iterations
SET node:AlreadySeen
WITH COLLECT([n, node]) AS distinct_pair_list // apoc gives distinct nodes only?
UNWIND distinct_pair_list AS pair
// I'm setting the graph name from the java app ... this is just a dummy name
WITH gds.graph.project("project_graph_1", pair[0], pair[1]) AS g
RETURN {
projection_name: g.graphName,
node_count: g.nodeCount
}
Again, I've to run this query like 400 times to project 400 minigraphs. Then I find top 10 components by transaction amount in each of those 400 projections and put them into a list. From the list, I then pick actual top 10 transactions! Welp!
I want to know what I can do further improve my projection times? Should I add a filter for only "ONLINE" transactions in the first MATCH as I only want those? I am using neo4j community at the moment and can't scale beyond 4 threads.
Thanks in advance !!!
EDIT
This query projects the entire graph with this is very fast but takes ~20GB heap
CALL gds.graph.project("project_graph_1", "*", "*") YIELD graphName, nodeCount, relationshipCount
Is there any way to project just Transaction nodes? I don't really understand why projecting all the nodes is faster than projecting just Transaction nodes. Likely because of all the traversals I'm doing in my initial query?