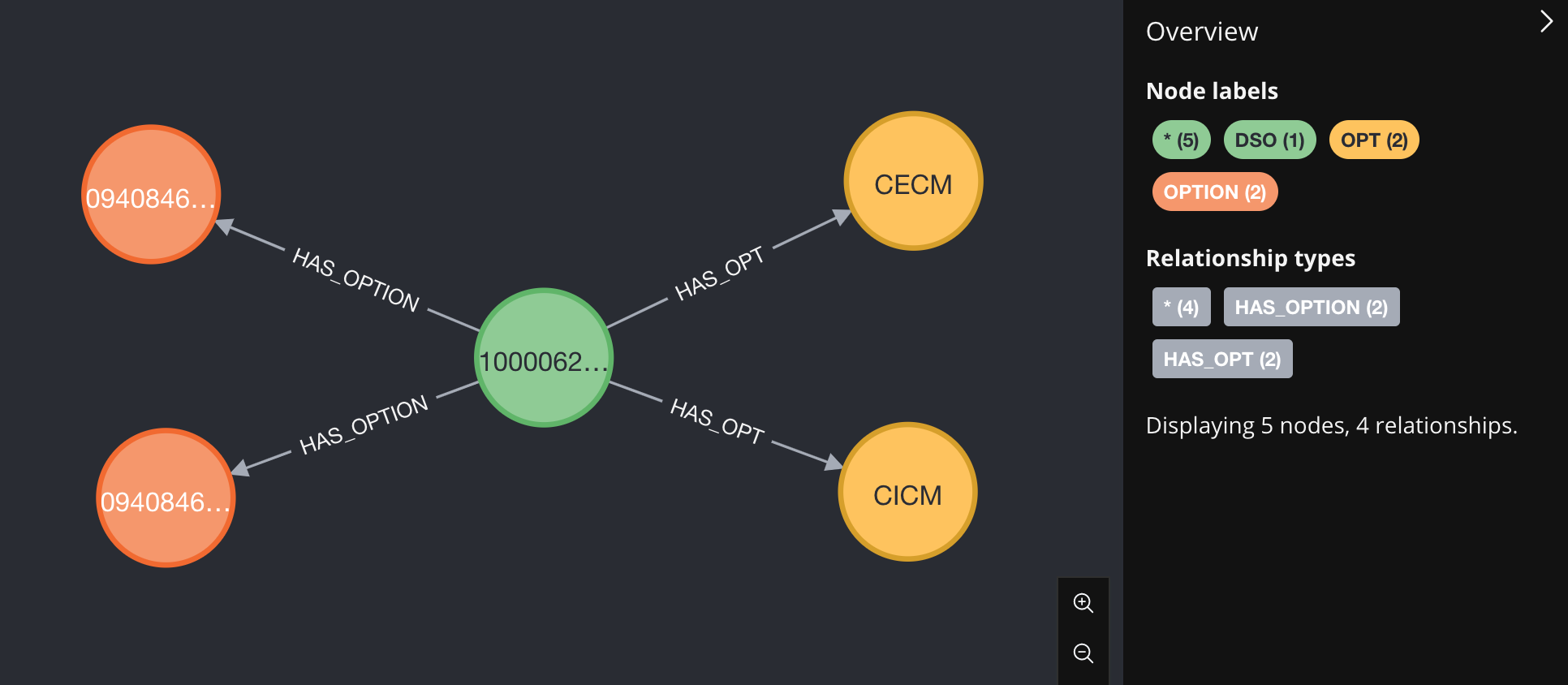
Ok. I was able to reproduce the issue using MySqlWorkbench to investigate the difference. It turns out if you import the data using merge (as below), it will create triplets that are not in the original data. This results in more rows in the neo4j database when the rows are joined and exported.
load csv with headers from "file:///sample_data.csv" as row
merge(option:OPTION{option_cd:row.OPTION})
merge(opt:OPT{opt_cd:row.OPT})
merge(dso:DSO{dso_cd:row.DEALER_SALES_ORDER})
merge(option)<-[:HAS_OPTION]-(dso)-[:HAS_OPT]->(opt)
When the data is joined (as below), there are 633 rows, while the original data file only had 413.
Match (option:OPTION)<-[:HAS_OPTION]-(dso:DSO)-[:HAS_OPT]->(opt:OPT)
return opt.opt_cd, option.option_cd, dso.dso_cd
I imported your data and an export from above query into a MySql database. I then looked at the results of an outer join of the neo4j data to your original data. It showed there were rows in the neo4j data that were not in yours. These obviously changed the results of your aggregation query.
I then changed the neo4j import query to use create instead of merge. The thought was this would create exactly the correct triplet pairs in the database.
load csv with headers from "file:///sample_data.csv" as row
create(option:OPTION{option_cd:row.OPTION})
create(opt:OPT{opt_cd:row.OPT})
create(dso:DSO{dso_cd:row.DEALER_SALES_ORDER})
create(option)<-[:HAS_OPTION]-(dso)-[:HAS_OPT]->(opt)
When I did this and run the aggregation query, I got the correct counts.
What I believe is happening is that the merge is creating the correct relationships between pairs of codes (opt_cd to dso_cd and option_cd to dso_cd), but when joined using the match pattern across all three entities, it created relationships between opt_cd and option_cd that do not exist in your original data. This is not a defect in the queries. I believe it is a defect in your data model. It assumes if there is a relationship between a specific dso_cd and option_cd, and there is a relationship between the same dso_cd and an opt_cd, then there is a relationship between the corresponding option_cd's and opt_cd's, which is obviously not true.
Typically we create nodes in a graph database that correspond to domain entities, so we can investigate complex relationships between these entities. A graph database is great when these relationships result in a network of deep relationships of varies lengths. These scenarios are not handled well by a relational database. In my option, if the entity relationships are only one level deep, as as in one-to-many, many-to-one, or many-to-many, then a relational database is a good choice.
Is there a reason you chose to create these three entities?