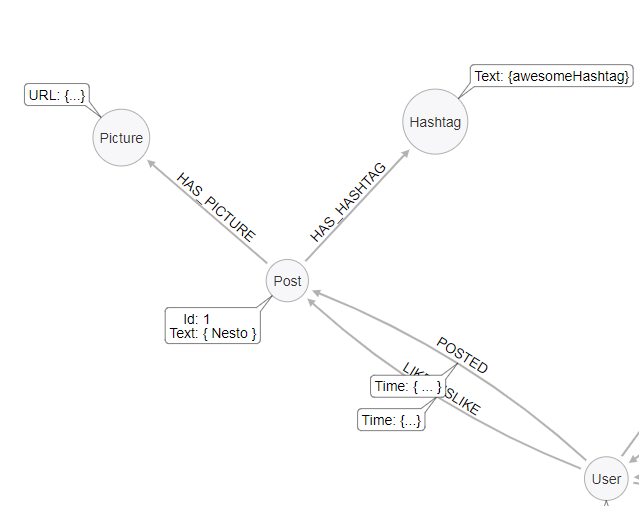
My question is: How query needs to look if i want to get all posts with all its data (post can have more than one picture, hashtag and to count how many likes and dislikes it has)?
If this is impossible is it better to get all posts with simple query and then for each post i get other data (one query for every relationship)? Is this approach bad and why?
You can get what you need in the same query. We can use pattern comprehension to find potential matches and extract information from that into a list, or collect the nodes themselves if needed. We can also get the size() of a pattern using specific relationships to get the degree of those relationships (# of likes and dislikes).
For example:
MATCH (p:Post)<-[:POSTED]-(user)
RETURN p, [(p)-[:HAS_PICTURE]->(pic) | pic.URL] as picURLs, [(p)-[:HAS_HASHTAG]->(tag) | tag.Text] as hashtags, size ((p)<-[:LIKE]-()) as likes, size((p)<-[:DISLIKE]-()) as dislikes, user
Shouldn't be a performance difference, pattern comprehension is like doing an OPTIONAL MATCH then a collect(). This is useful when you want to keep the original cardinality (number of rows) instead of increasing them with the OPTIONAL MATCH (or MATCH)
I need to do some more testing, but pattern comprehension is performing better interestingly. I've also noticed if within the pattern if I specify a label on the pattern vs. not, the execution plan was also vastly different. Whatever the explanation, just wanted to say thank you for introducing a new syntax to me!
Cypher version: CYPHER 3.4, planner: COST, runtime: SLOTTED. 351299 total db hits in 615 ms.
PROFILE
MATCH (otherProfile:Profile {profile_id: 123})-[otherProfileFavorite:FAVORITE]->(proj:Project)
WITH proj,
otherProfile.profile_id AS profile_id,
otherProfile.user_id AS user_id,
otherProfileFavorite.created_date AS created_date
ORDER BY created_date DESC
OPTIONAL MATCH ()-[rel:LIKE|FAVORITE|SHARE]->(proj)
WITH proj,
profile_id,
user_id,
created_date,
SUM(CASE Type(rel) WHEN "LIKE" THEN 1 ELSE 0 END) AS likeCount,
SUM(CASE Type(rel) WHEN "FAVORITE" THEN 1 ELSE 0 END) AS bmCount,
SUM(CASE Type(rel) WHEN "SHARE" THEN 1 ELSE 0 END) AS shareCount
OPTIONAL MATCH (authProfile:Profile {profile_id: 456})-[authProfile_r:LIKE|FAVORITE]->(proj)
RETURN proj.project_id AS project_id,
profile_id,
user_id,
created_date,
likeCount,
bmCount,
shareCount,
SUM(CASE Type(authProfile_r) WHEN "LIKE" THEN 1 ELSE 0 END) AS currentProfLiked,
SUM(CASE Type(authProfile_r) WHEN "FAVORITE" THEN 1 ELSE 0 END) AS currentProfBooked
ORDER BY created_date DESC
Cypher version: CYPHER 3.4, planner: COST, runtime: SLOTTED. 8303 total db hits in 140 ms.
PROFILE
MATCH (otherProfile:Profile {profile_id: "123"})-[otherProfileFavorite:FAVORITE]->(proj:Project)
RETURN proj.project_id AS project_id,
otherProfile.profile_id AS profile_id,
otherProfile.user_id AS user_id,
otherProfileFavorite.created_date AS created_date,
size(()-[:LIKE]->(proj)) AS likeCount,
size(()-[:FAVORITE]->(proj)) AS bmCount,
size(()-[:SHARE]->(proj)) AS shareCount,
size((:Profile {profile_id: "456"})-[:LIKE]->(proj)) AS currentProfLiked,
size((:Profile {profile_id: "456"})-[:FAVORITE]->(proj)) AS currentProfBooked
ORDER BY created_date DESC
Thanks for this thread and the helpful and interresting answers provided. I do have a quick question following the use of Pattern Comprehension. I See that you can return values such as the picUrls in the example you provided. Is it possible to return a boolean based on the existence of a pattern in the return clause ?
I tried this but am not happy with the empty result
return [(p)-[:HAS_PICTURE]->() | true] as hasPic // true if relation exists and empty otherwise
I tried size also, wich is better as it returns 0 or an integer
return size((p)-[:HAS_PICTURE]->()) as hasPic // an int if relation exists and 0 otherwise