





I am trying to write a CTE ( Common Table Expression ) Cypher query. Does Neo4j support writing CTE? I am aware of the Cypher WITH clause. Despite the same naming it seems to me that in Cypher - unlike SQL - the clause only passes the result of the previous query part (which was invoked on real graph data in Neo4j database) to subsequent streaming.
Cypher does not support anything like that. Query results are passed along row-by-row to the next match or merge clause, so you can further refine your results. What is it you are trying to accomplish, so we can see if we can help you get up and going?
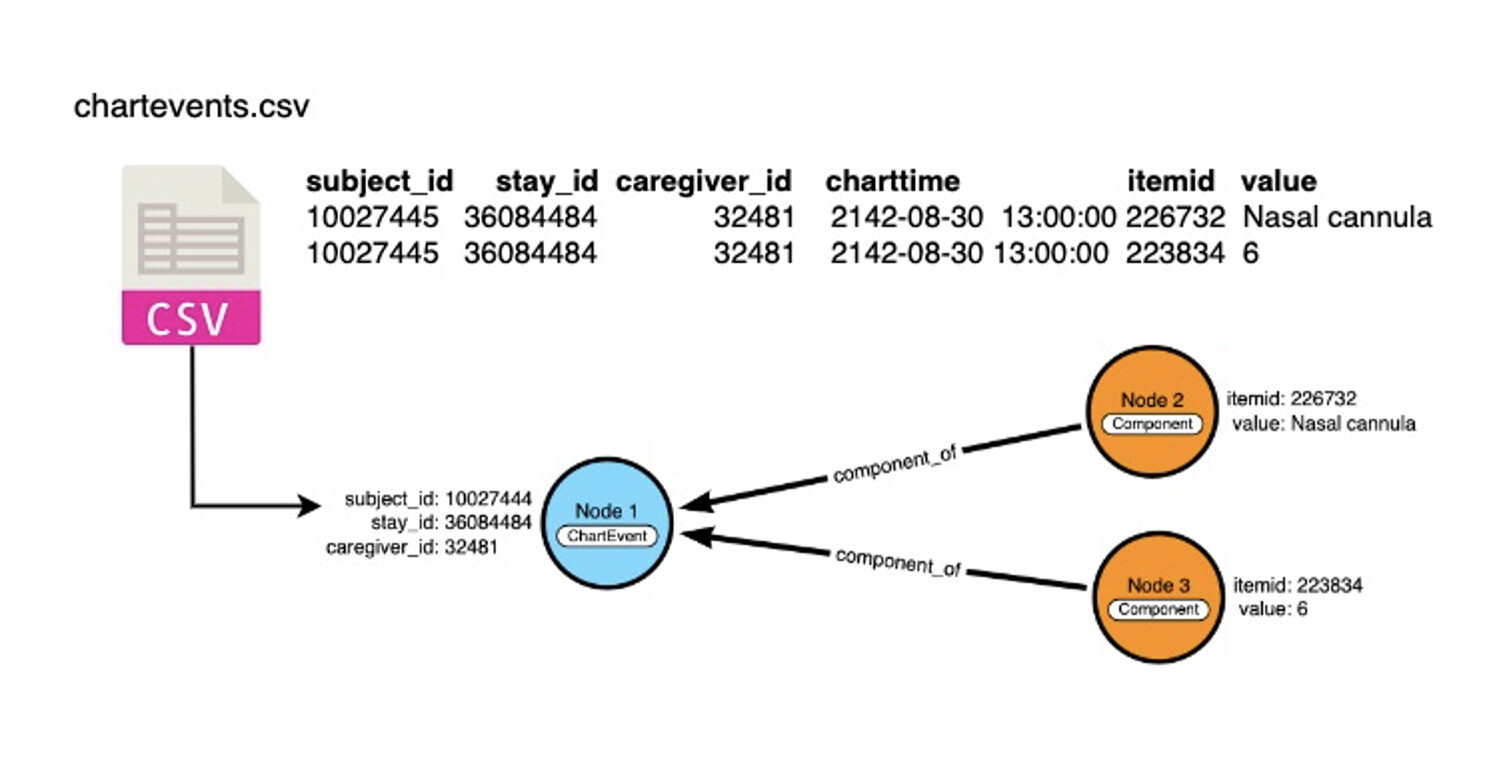
Thank you for responding. Basically we are trying to convince one of the federal agency to use Neo4j instead of Postgres and we are using MIMIC IV datasets as POC. We converted each table into a node and the columns into properties , and we converted the foreign keys and associated tables into edges. I am new to Cypher. I am trying to covert this SQL query to Cypher mimic-code/mimic-iv/concepts_postgres/measurement/oxygen_delivery.sql at main · MIT-LCP/mimic-code · GitHub
I have one node chartevents with 11 properties. oxygen_delivery.sql query only select from chartevents table but it create 4 CTE and joins two CTE. Is it possible to convert the oxygen_delivery.sql to Cypher? Please let me know if I am not in the right direction.
There is no equivalent to the SQL 'with' clause or nested queries in Neo4j, where the query results from either is used as the source of the records for another SQL query.
In Neo4j you start with a match statement to get a set of rows, where each row satisfies the match pattern. Each subsequent match executes row-by-row to further refine or expand the results from the previous match. In essence, it is expected that each match is correlated to the previous match. The exception is if you intentionally have two uncorrelated sequential match statement that will produce a Cartesian product of the results from each match.
Stripping away the noise from the oxygen delivery sql query, it looks like you have two tables with similar data and you are joining them to returning values with preference from one table, using the other table as a backup (implemented with COALESCE). Then there is some aggregation calculated over the resulting data set.
Since cypher and sql are very different, I think it is best not to try to implement the sql query in cypher, but instead understand the end result of the sql query and implement that in cypher. You may find that doing things in cypher is a lot easier than in sql when the data is well represented in a graph structure; especially when doing hierarchical queries.
I would be glad to try to help out if you can provide your data model and what data you need to extract/calculate. A good tool to model your data model visually is arrows.app (https://arrows.app/).
1 Like
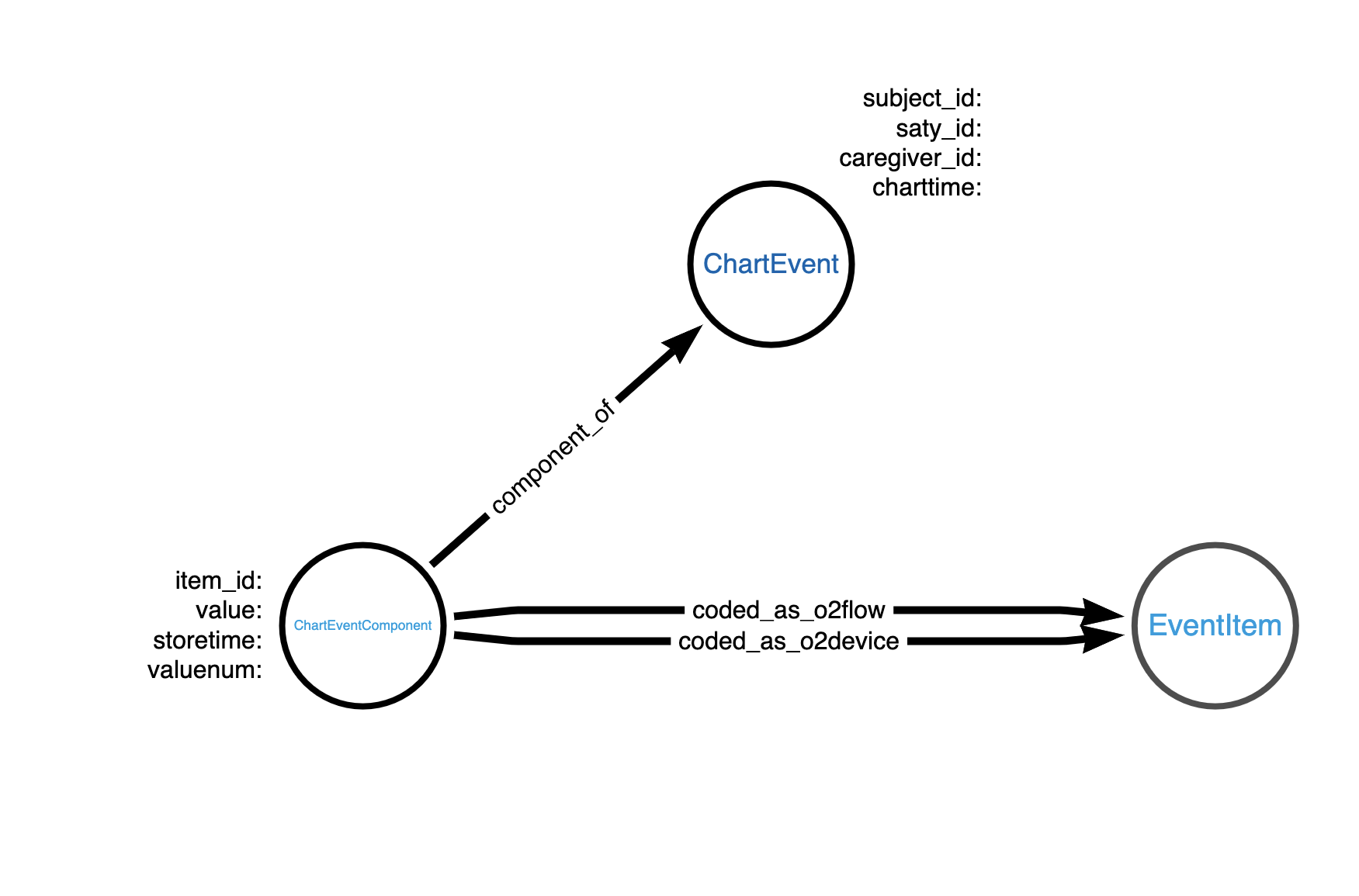
Thanks @glilienfield for your help. I break down the ChartEvent node into this simple model. I wrote this query for the oxygen_delivery but it is not returning any records
MATCH (ce:ChartEvent) <- [:component_of] - (cec:ChartEventComponent) - [:coded_as_o2flow] -> (:EventItem)<- [:coded_as_o2device]-(cec:ChartEventComponent)
WITH ce.subject_id AS subject_id_ce , ce.stay_id AS stay_id_ce , ce.charttime AS charttime_ce, CASE WHEN cec.itemid IN [223834, 227582] THEN 223834 ELSE cec.itemid END AS itemid_cec, cec.value AS o2_device, cec.valuenum AS valuenum_cec, cec.valueuom AS valueuom_cec, cec.storetime AS storetime_cec, collect([ce.subject_id]) as col unwind range(0, size(col)-1) as rn1
WITH collect(stay_id_ce) as stay_id_ce , subject_id_ce as subject_id_ce , charttime_ce as charttime_ce, itemid_cec as itemid_ce, valuenum_cec as valuenum_ce, rn1 as rn, o2_device AS o2_device
UNWIND stay_id_ce as stay_id
WITH subject_id_ce, charttime_ce , MAX(stay_id) AS max_stay_id , MAX(CASE WHEN itemid_ce = 223834 THEN valuenum_ce ELSE NULL END) AS o2_flow
, MAX(CASE WHEN itemid_ce = 227287 THEN valuenum_ce ELSE NULL END ) AS o2_flow_additional
, MAX(CASE WHEN rn = 1 THEN o2_device ELSE NULL END) AS o2_delivery_device_1
, MAX(CASE WHEN rn = 2 THEN o2_device ELSE NULL END) AS o2_delivery_device_2
, MAX(CASE WHEN rn = 3 THEN o2_device ELSE NULL END) AS o2_delivery_device_3
, MAX(CASE WHEN rn = 4 THEN o2_device ELSE NULL END) AS o2_delivery_device_4
RETURN
subject_id_ce
, max_stay_id
, charttime_ce
, o2_flow
, o2_flow_additional
, o2_delivery_device_1
, o2_delivery_device_2
, o2_delivery_device_3
, o2_delivery_device_4
Do you have some sample data I can test with? A cypher script to create it would be ideal.
The first thing to verify is that you get back results from the match statement. What do you get back from this query:
MATCH (ce:ChartEvent) <- [:component_of] - (cec:ChartEventComponent) - [:coded_as_o2flow] -> (:EventItem)<- [:coded_as_o2device]-(cec:ChartEventComponent)
RETURN *
Question: do you really need two relationships between ChartEventComponent and EventItem? Do they not always come in pairs? Could you use 'HAS_EVENT_ITEM' instead? BTW, best practice is to have relationship types in snake case and labels in pascal case.
The above query will only return results when both relationships exists.
1 Like
This return no records
> MATCH (ce:ChartEvent) <- [:component_of] - (cec:ChartEventComponent) - [:coded_as_o2flow] -> (:EventItem)<-[:coded_as_o2device] - (cec:ChartEventComponent)
> RETURN *
The SQL query has one CTE items ids for the O2 flow and one item id for the O2 device. Thats why we created two relationship to the EventItem.
Can I start the query with the below two MATCH? or is it going to do Cartesian products?
MATCH (ce:ChartEvent) <- [:component_of] - (cec:ChartEventComponent) - [:coded_as_o2flow] -> (:EventItem)
MATCH (ce:ChartEvent) <- [:component_of] - (cec:ChartEventComponent) - [:coded_as_o2device] -> (:EventItem)
Ok, your query is written so that the EventItem is the same for the 02 flow and 02 device. Is that correct, or does each one have their own EventItem? This is what you are attempting with the two matches above. Yes, they will produce a Cartesian product. How many EventItems will be returned from each?
What do you get back from this query:
MATCH (ce:ChartEvent) <- [:component_of] - (cec:ChartEventComponent) - [:coded_as_o2flow] -> (e:EventItem)
RETURN '02flow' as type, ce, cec, e
UNION
MATCH (ce:ChartEvent) <- [:component_of] - (cec:ChartEventComponent) - [:coded_as_o2device] -> (e:EventItem)
RETURN '02device' as type, ce, cec, e
BTW- in your original query you are not using the EventType nodes if they were returned in the query. Why are you including them in the cypher pattern? Do you need to ensure that a relationship exists, otherwise you don't want the ChartEvent and ChartEventComponent in the result?
1 Like
I just reviewed the sql code again. What I see is basically two queries, both of which are over the mimiciv_icu.chartevents table.
In one query (ce_stg1) you are extracting some columns for all records where the 'value' is not null and 'itemId' is one of three values. From the comments, it looks like this data represent the 02 flow data. The ce_stg2 query basically takes the results from ce_stg1 and assigns row numbers based on a partitioning over subject_id, charttime, itemid.
In the other query, you are extracting the same columns, but now the results are restricted to just itemid = 226732 . Based on the alias to value, this looks to represent the 02 devices.
These two results are then merged in query (stg), where the values in the ce_stg2 query are preferred to the corresponding value in the o2 query. This is done with the coalesce function. Finally, the query filters our all row numbers assigned during partitioning to just the first row number.
The actual query that utilizes these results is calculating max values for each unique pair of subject_id and chart time values.
All the attributes you are using in these queries are properties of the ChartEvent and ChartEventComponent nodes AND the relationship type to the EventItem tells you if the ChartEvent is related to an 02 flow or 02 device.
Base on the sql query, it looks like the identification of whether a ChartEvent/ChartEventComponent is related to an 02 flow or 02 devices is based on the value of the ChartEventComponent's item_id. If this is correct, do you need EventItem nodes?
1 Like
Yes, we need the relationship to EventItem node because all Itemids are in the EventItem table. so we have two relationships coded_as_o2device and coded_as_o2flow from ChartEventComponent to EventItem
What attributes are properties of the EventType?

We have 654,557,219 nodes and 1.204.931.471 relationships in the database and I am using Neo4j community edition. When I run the below query it takes long time till Neo4j freeze and stop working. so there is no result for the below query
MATCH (ce:ChartEvent) <- [:component_of] - (cec:ChartEventComponent) - [:coded_as_o2flow] -> (e:EventItem)
RETURN '02flow' as type, ce, cec, e
UNION
MATCH (ce:ChartEvent) <- [:component_of] - (cec:ChartEventComponent) - [:coded_as_o2device] -> (e:EventItem)
RETURN '02device' as type, ce, cec, e
This query return data but it is slow
MATCH (ce:ChartEvent) <- [:component_of] - (cec:ChartEventComponent) - [:coded_as_o2flow|coded_as_o2device] -> (:EventItem)
Return *
That is because you have a lot of entities and there is no constraints on this query. You are returning results for every single matching path in your entire database. Typically, a query begins with matching on a small set of entities, then expanding the path to find related nodes.
It looks like you are trying to use Neo4j for data analytics. I really don't think this is a good use case for a graph database.
Now, if you create a graph of patients, encounters, lab results, medications, diagnosis, interventions, etc., you may be able to use it to find out insights within the data.
1 Like