Hello,
My problem is the following.
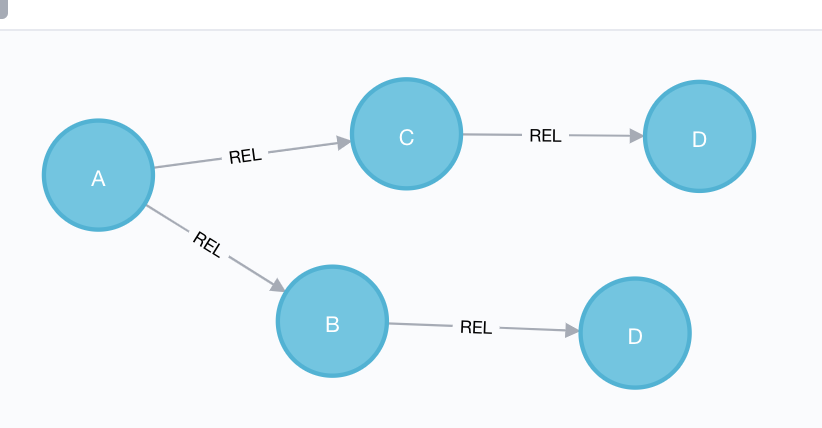
I have 4 nodes A B C D.
I have relationships with percentage.
I consider that two nodes are in the same cluster if it exists a relationship with a percentage above 50%.
“A - > B [100]“ means A owns B with 100% share, so A and B must be in the same cluster.
My data are:
A->B[100]
A->C[100]
B->D[40]
C->D[30]
So A, B and C are in the same cluster.
But D must be in the same cluster because the relationships between the cluster and D are above 50 (40+30).
Have you an idea to create automatically the correct cluster?
Best regards,
Alexandre
Thanks for you help.
But the value of percent is a property of relationship, not of a node.
Moreover, the goal is to build an algorithm (or to reuse one) in order to build a new relationship between the cluster and the node D since the sum of percents is above 50.0. I think that the final relationship created must have "A" as parent; because A is the first common parent of B and C.
Is it more clear ?