In version 3.5.11.0 of the Neo4j Graph Algorithms Library we added the Approximate Nearest Neighbors or ANN procedure.
ANN leverages similarity algorithms to efficiently find more alike items. In this post, we’ll look at our motivation for creating this algorithm, where it can be used, and will show how to use it with the help of a worked example.
You can download the Graph Algorithms Library from the Neo4j Download Center or install it into Neo4j Desktop via the Graph Algorithms Playground Graph App

It’s now been almost a year since we added similarity algorithms to the Neo4j Graph Algorithms Library, and they’ve quickly become some of the most widely used ones in the library.
A popular use case is creating a nearest neighbor graph or similarity graph. Such a graph contains relationships between two nodes a and b if the distance between aand bis among the k-th smallest distances from ato all other nodes.
The distance between nodes would be computed by using one of the similarity algorithms to compare attributes such as schools attended, movies rated, or product purchased in common.
This graph may then be used as part of a recommendation system. We might make recommendations in the following domains:
- e-commerce — find people similar to me and recommend products that they bought but that I haven’t yet bought
- content — find articles similar to each other and recommend them to readers
- photos — if you like this image you might also like these images
Ok that sounds useful, but why do we need this ANN thing?
While this approach does work, it’s computationally expensive.
We have to compare every item with every other item, which gives us O(n^2) complexity or (numberOfNodes*numberOfNodes-1)/2 computations. It’s very much a brute force approach.
For example, if we wanted to compute the similarity of 10,000 items, we’d need to do:
10,000*9,999 / 2 = 49,995,000computations
That doesn’t sound too bad, but what if we increase it by a factor of 10, and now want to compute the similarity of 100,000 items? We’d now need to do:
100,000 * 99,9999 2 = 4,999,950,000 computations, which would take a long time to complete.
Introducing Approximate Nearest Neighbors (ANN)
The Approximate Nearest Neighbors algorithm reduces the amount of computation needed to build a similarity graph because we are no longer comparing every node with every other node.

We’ve implemented an algorithm called NN-Descent, which is described in the Efficient K-Nearest Neighbor Graph Construction for Generic Similarity Measures paper.
The paper describes a simple but efficient algorithm for creating nearest neighbor similarity graphs.
Pseudo-code for the algorithm can be seen in the diagram below:

The trade off with this algorithm is that we are computing the approximate nearest neighbors, rather than absolute nearest neighbors as with the brute force approach.
Recall Definition
Having said that, we’ve found that we get a recall rate of 90% or above on the test data sets on which we’ve tried out the algorithm.
When should we not use it?
As with most things, ANN isn’t a silver bullet, so we don’t want to use it everywhere.
If we’re trying to compute a nearest neighbors graph for a small data set, the brute force approach still makes sense. On very tiny data sets containing 10s of nodes, the ANN approach will require more computation and produce worse results.
Equally, if we’re making for high-stakes decisions, e.g. if you’re trying to estimate a medical prediction, you might be very sensitive to false positives and the longer compute time of the brute force approach would be acceptable.
Let’s see it in action
The ANN Benchmarks GitHub repository contains data sets that we can use to test our algorithm.

We’ll use with the Fashion-MNIST dataset, which contains 60,000 of Zalando’s article images.
Each example has a 784 digit embedding that represents the pixels in the image.
Importing Fashion MNIST
The data is in HDF5 format, so we’ll need to convert that into CSV format before we can more import into Neo4j. We’ll then use the apoc.load.csv procedure to create a node representing each image and store the embedding in the property embedding on the node.
Fashion MNIST Data set in Neo4j
Building a brute force nearest neighbors graph
Once we’ve got the data imported we’re ready to create our nearest neighbors similarity graph. We’ll start with the brute force approach, which we can do by executing the Euclidean Distance Similarity algorithm:
MATCH (p:MNISTItem)
WITH {item:id(p), weights: p.embedding} as userData
WITH collect(userData) as data
CALL algo.similarity.euclidean(data, {
topK:20, write:true,
showComputations: true,
writeRelationshipType: "SIMILAR20"
})
YIELD nodes, similarityPairs, computations
RETURN nodes,
apoc.number.format(similarityPairs) AS similarityPairs,
apoc.number.format(computations) AS computations
We’ve used some config parameters in this procedure call. Let’s explore those:
- topKspecifies the upper bound for the number of similar nodes to find
- writeRelationshipType specifies the relationship type to use for our nearest neighbor graph
- showComputations keeps track of the number of computations done in generating the nearest neighbor graph
Building an approximate nearest neighbors graph
And now let’s do the same thing using our new Approximate Nearest Neighbors procedure:
MATCH (p:MNISTItem)
WITH {item:id(p), weights: p.embedding} as userData
WITH collect(userData) as data
CALL algo.labs.ml.ann("euclidean", data, {
topK:20, write:true, showComputations: true, iterations: 50,
writeRelationshipType: "SIMILAR20_APPROX,
p: 0.5
})
YIELD nodes, similarityPairs, computations, iterations, scanRate
RETURN nodes,
apoc.number.format(similarityPairs) AS similarityPairs,
apoc.number.format(computations) AS computations,
iterations,
scanRate
There are a few config options of interest in this procedure call:
- iterations specifies the upper bound for number of iterations that the algorithm will execute
- topKspecifies the upper bound for the number of similar nodes to find
- p specifies the sample rate i.e. how many relationships to consider when sampling the graph. For example, if topK is 20 and p is 0.5 we’d sample 20*0.5 = 10 relationships.
- writeRelationshipType specifies the relationship type to use for our nearest neighbor graph
- showComputations keeps track of the number of computations done in generating the nearest neighbor graph. We’ll use this so that we can compare the number of computations against the brute force approach.
Evaluating the approximate nearest neighbors graph
Now we’re going to compare our approximate nearest neighbors graph with the bruce force variant. The following query:
- iterates over each example, collecting both the brute force and approximate neighbors into lists
- for each example, computes the intersection of those lists
- for each example, computes a recall value i.e. how many of the items in the approximate neighbors list were in the brute force neighbors list
- computes the average recall value across all examples
match (r:MNISTItem)
WITH r,
[(r)-[:SIMILAR20]->(i) | id(i)] AS bruteForce,
[(r)-[:SIMILAR20_APPROX]->(i) | id(i)] AS approx
WITH r, bruteForce, approx,
apoc.coll.intersection(approx, bruteForce) AS intersection
WHERE size(bruteForce) > 0
WITH r,
size(intersection) * 1.0 / size(bruteForce) AS recall,
bruteForce, approx
return avg(recall);
We create approximate nearest neighbors graph using different sampling rates, and the following table shows number of computations, computation time, as well as recall for each of these configurations:
Brute Force vs ANN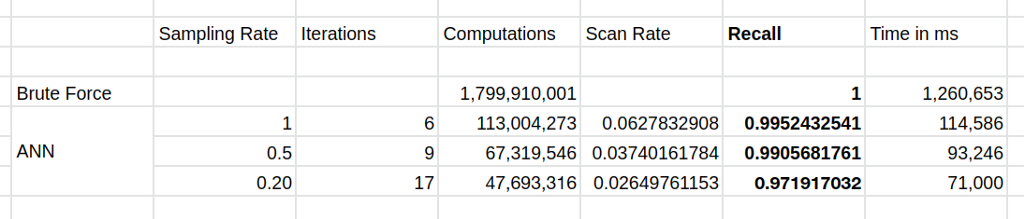
Summary
In this post we’ve learnt how to use the approximate nearest neighbor algorithm in the Neo4j Graph Algorithms Library.
If you enjoyed learning how to apply graph algorithms to make sense of data, you might like the O’Reilly Graph Algorithms Book that Amy Hodler and I wrote.
You can download a free copy from neo4j.com/graph-algorithms-book

![]()
Building a similarity graph with Neo4j’s Approximate Nearest Neighbors Algorithm was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.