My graph is defined as follows:
Nodes:
:Object(id, name)
:Attribute(name, concept_type)
Edges: Objects may point to Attribute using :HAS_ATTRIBUTE relation type.
I have about 1M Object nodes and 1000 Attribute nodes. All of the properties are indexed.
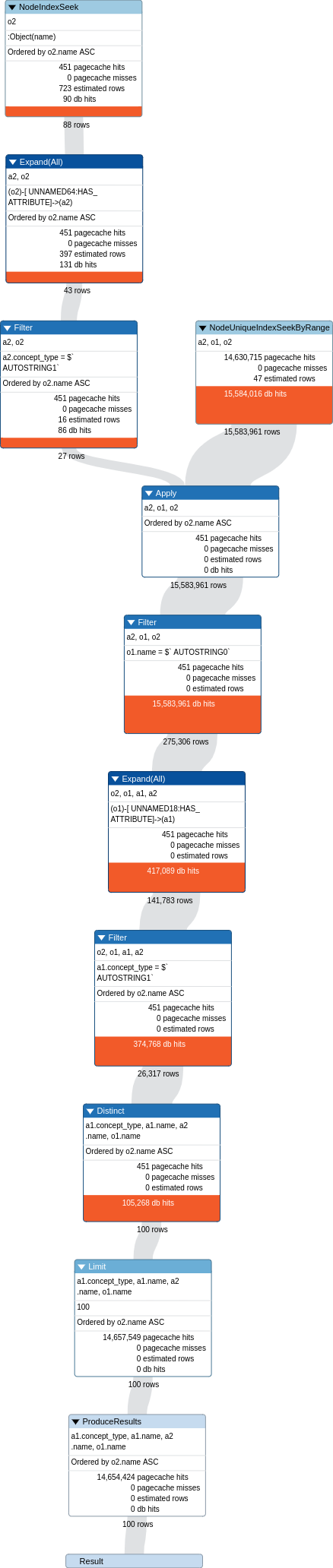
I am trying to get objects whose names are same but have different attribute names for same attribute type (e.g., men with different colored hairs). The query is shown below. Despite placing a limit on the following query, it is running very slow.
MATCH (o1:Object)-[:HAS_ATTRIBUTE]->(a1:Attribute),
(o2:Object)-[:HAS_ATTRIBUTE]->(a2:Attribute)
WHERE o1.id > o2.id
AND o1.name = o2.name
AND a1.name > a2.name
AND a1.concept_type = a2.concept_type
AND a1.concept_type = 'color'
RETURN DISTINCT o1.name,a1.name,a2.name, a1.concept_type
LIMIT 1000
Could you provide tips on speeding this up. Would I be better off making attributes properties of Object instead of having edges from Object to Attribute? My only concern is same object can have multiple values for same attribute type.
Neo4j version = 3.5.6